II · my story · why this matters
I was you. Then I built this.
Before
Picking models was a nightmare.
I'd pay $50+ a week on Anthropic just to keep up.
Every new model launch made me re-test my whole stack.
Half the open models couldn't do tool calling well enough for real agent work.
The other half were cheap but capped at 200K context — my Obsidian vault wouldn't fit.
And every time a frontier model launched, I waited weeks for my agent harness to catch up.
Then Qwen3.7-Max dropped — and Hermes Agent merged it the same week.
After
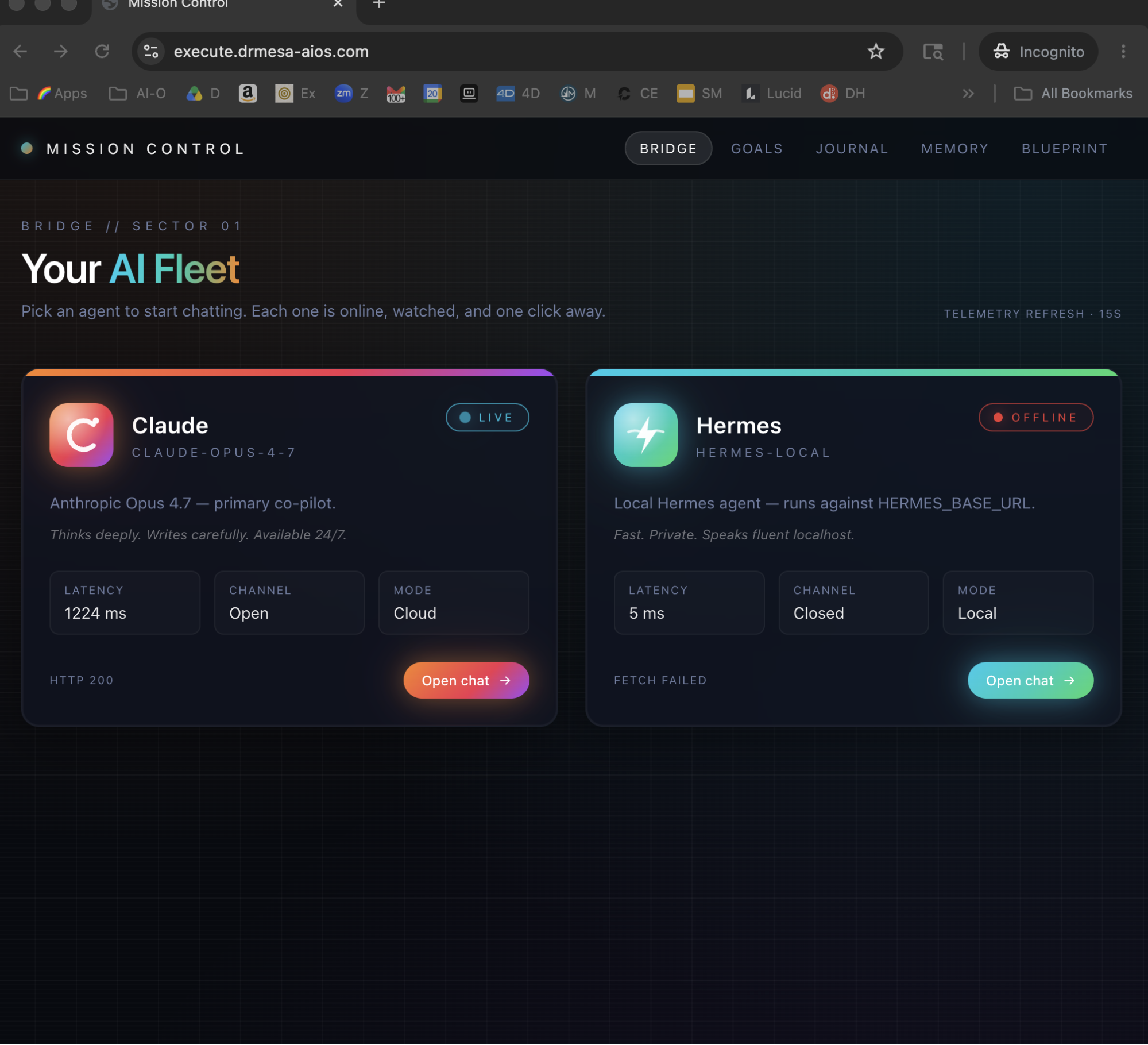
Now I open the dashboard and pick Qwen3.7-Max.
The model is at the top of every benchmark that matters.
Hermes wired it in via PR #32809 — verified live, all tests green.
My input cost dropped to $1.25 per million tokens with cached prefixes at $0.25.
The full vault + repo + brief fits in one shot at 1M tokens of context.
And I can set a goal Sunday night and wake up to a 30-hour autonomous run that's actually finished the work.
You can have this too. Same merge. Same model. Same Hermes. Same Agent OS.
Before you scroll on —
Commit to transitioning today. Not tomorrow.
You've seen the proof above. Real merge. Real benchmarks. Real members shipping with it.
The next 10 minutes show exactly what Qwen3.7-Max + Hermes Agent unlocks inside Agent OS.
So here's the deal.
If you're reading this — promise yourself one thing right now. You're going to finish this guide AND swap your default Hermes model to Qwen3.7-Max before you sleep tonight. Just one config change. Because the moment you make this transition, your whole agent workflow gets cheaper, longer, and smarter at the same time.
The people sitting still are paying double for the same output. The people switching today are the ones who'll be six months ahead by next quarter.
Be one of those people.
Commit to the transition. Commit to flipping the default today. This changes everything about how your agents run.
IV · the framework
The Goldie Frontier Stack™.
Five layers that turn a brand-new model release into a daily-driver agent system you can ship from.
Each layer is a benefit you feel the moment it's wired in. Together they're why "Qwen3.7-Max just launched" isn't a news item — it's a workflow upgrade. The stack compounds: better model + better harness + better caching + bigger context + longer loops = something that didn't exist last week.
The five layers — Model, Harness, Cache, Context, Loop.
i.
Model — Qwen3.7-Max.
The frontier-tier model that ships with the frontier-tier benchmarks. GPQA Diamond 92.4 (beats Opus-4.6's 91.3). HMMT Feb 97.1 (beats Opus-4.6's 96.2). Apex 44.5 (top score). MCP-Atlas 76.4 (top score). Available via OpenRouter and Alibaba Cloud Model Studio. 1M context. 50% off launch pricing right now.
ii.
Harness — Hermes Agent.
The #1 app using Qwen3.7-Max on OpenRouter this month — 5.28B tokens, ahead of OpenClaw, Kilo Code, and Claude Code. Tool calling, persistent memory, scheduled automations, subagents — all wired to use this model as the default backbone via PR #32809.
iii.
Cache — explicit prompt caching.
Cache reads at $0.25 per million tokens versus $1.25 for fresh input. Real-world cache hit rate on repeated prefixes: 83.2%. Effective input price drops to around $0.43 per million. Your daily Hermes runs become a fraction of what they'd cost on Anthropic.
iv.
Context — 1 million tokens.
Your whole Obsidian vault + the whole repo + the brief + a year of past conversations — all in one shot. No more chunking, no more retrieval-augmented duct tape, no more "the agent doesn't remember what you told it yesterday." The context becomes the memory.
v.
Loop — 35-hour autonomous runs.
Qwen3.7-Max ran a 35-hour autonomous kernel optimisation with 1,158 tool calls on hardware it had never seen — and finished at 10× speedup. That's the kind of long-horizon coherence that turns Hermes Goal Mode into "set it Sunday, ship it Friday" instead of "babysit it for an hour."
X · benefit three
Explicit prompt caching. 83% hit rate.
Cached prefixes glow brighter — reused tablets pull from the archive at a fraction of the original cost.
iii.
Why this matters to you.
You stop paying full price for the same prompt prefix over and over.
Qwen3.7-Max supports explicit prompt caching with very aggressive pricing — cache reads at $0.25 per million tokens versus $1.25 for fresh input. That's an 80% discount on every cached token.
For Hermes-style agent workflows where you reuse the same system prompt, the same agent instructions, the same MCP definitions, the same Obsidian context across hundreds of calls — the cache hit rate runs around 83%. That's most of your input cost gone.
Effective input price in practice: somewhere between $0.43 and $0.50 per million tokens.
What you gain: a daily Hermes bill that looks like a coffee, not a SaaS sub.
You do this
Inside Hermes, structure your agent prompts so the long shared prefix (system prompt, brand voice, SOPs, MCP schemas) stays identical across calls — only the user's actual question changes at the end. The caching engine catches the prefix automatically. You don't have to do anything else.
Thinking it?
"I don't repeat prompts often enough for caching to matter."
You repeat them more than you think.
Every Hermes goal you run has the same system prompt. Every chat with the same agent uses the same skills file. Every Obsidian-grounded query loads the same vault prefix. The "varied part" of your prompt is usually the last 1% — everything before it is identical.
That 99% is what gets cached. That's where the 83% hit rate comes from.
You don't have to plan for caching. The structure of agent work caches itself.
✓
OpenRouter dashboard shows 83.2% cache hit rate across Qwen3.7-Max traffic in the last 7 days.
XI · benefit four
1 million tokens of context.
iv.
Why this matters to you.
You stop chunking and start dropping.
1M context = your whole Obsidian vault (or a big chunk of it) + the whole project repo + the brief + a year of past conversations + the full meeting transcripts — all in one call. No retrieval. No chunking. No RAG plumbing.
The recall benchmark is real: MRCR-v2 128k at 90.4 — the model can actually find the needles you drop in. Most "long context" models fall over here. Qwen3.7-Max doesn't.
What you gain: your AI stops forgetting the context you already gave it.
You do this
Next time you start a fresh agent session, paste your whole brand-voice doc, your last three pieces of content, your top SOPs, and the brief — all at once. Then ask the agent to write. The output sounds like you on the first try, not the fifth.
Thinking it?
"Long context always degrades quality on the actual answer."
Not on Qwen3.7-Max. MRCR-v2 128k = 90.4 (versus Opus-4.6 at 84).
The "lost in the middle" problem is real for older models. Qwen3.7-Max's training explicitly focused on long-context recall. The model finds what you put in it, regardless of where in the context it lives.
Plus caching means even if your prefix is huge, you pay $0.25/M for it after the first call.
You get the recall AND the cost stays low.
✓
Members report dropping entire Obsidian vaults into single Hermes calls and getting outputs that reference notes from anywhere in the dump.
XII · benefit five
35-hour autonomous runs.
An autonomous system caught mid-run — the kind of long-horizon loop Qwen3.7-Max sustains coherently for 30+ hours.
v.
Why this matters to you.
You stop babysitting your agent halfway through a job.
Qwen's own report documents a 35-hour fully autonomous kernel optimisation run — Qwen3.7-Max worked on hardware it had never seen before, did 1,158 tool calls across 432 kernel evaluations, redesigned the kernel architecture multiple times, and hit a 10× geometric mean speedup over the reference.
The other frontier models on the same task: GLM 5.1 reached 7.3×. Kimi K2.6 reached 5.0×. DeepSeek V4 Pro reached 3.3×. Qwen3.6-Plus (the previous version) reached 1.1×.
That's the kind of long-horizon coherence that turns Hermes Goal Mode from "set a task, hover" into "set a goal, sleep through it."
What you gain: autonomous overnight runs that actually finish productively, not just exit early.
You do this
Sunday night — open Hermes Goals. Type a long-horizon goal: build me a complete SEO site about [topic], including the blog index, individual blog posts, schema markup, internal linking, and deploy-ready HTML. Hit start. Close your laptop. Open Monday morning. Preview the site in your Workspace tab.
Thinking it?
"Autonomous runs always go off the rails after a few hours."
That was Qwen3.6-Plus. Qwen3.7-Max stayed on the rails for 35 hours straight.
The optimisation trajectory in Qwen's report shows sustained, non-trivial progress past 30 hours — the model was still finding meaningful improvements in the final stretch, not hallucinating or repeating itself.
This is the difference between "long context" (the model can read a lot) and "long horizon" (the model can think coherently for a long time). Most models have one. Qwen3.7-Max has both.
Your overnight goals stop being a gamble. They start being a workflow.
✓
Qwen Team's published benchmark — 35 hours, 1,158 tool calls, 10× speedup on Extend Attention Kernel optimisation.
XIII · the setup
Three lines plus a JSON block.
The whole config to make Qwen3.7-Max the default in Hermes (after PR #32809 lands in your install). Drop this into your Agent OS dashboard config — exact same pattern OpenClaw uses:
{
"models": {
"mode": "merge",
"providers": {
"modelstudio": {
"baseUrl": "https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
"apiKey": "DASHSCOPE_API_KEY",
"api": "openai-completions",
"models": [
{
"id": "qwen3.7-max",
"name": "qwen3.7-max",
"reasoning": true,
"input": ["text"],
"contextWindow": 1000000,
"maxTokens": 65536
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "modelstudio/qwen3.7-max"
}
}
}
}
Or if you're routing through OpenRouter (which is how Hermes is the #1 app on OpenRouter right now), swap the provider block for:
"openrouter": {
"baseUrl": "https://openrouter.ai/api/v1",
"apiKey": "OPENROUTER_API_KEY",
"models": [{ "id": "qwen/qwen3.7-max" }]
}
Two commands to wire it up if you're starting fresh:
hermes update
hermes config set agents.defaults.model.primary modelstudio/qwen3.7-max
That's it. Restart Hermes. The default model is Qwen3.7-Max. Your stack just got cheaper and longer-context at the same time.
"Three lines plus a JSON block. The hardest part is remembering to read the launch announcement."
Why this can't live on its own.
Qwen3.7-Max on its own is a frontier model. Hermes Agent on its own is a frontier harness. Inside Agent OS is where they become a frontier workflow.
a.
Shared vault across every agent.
Hermes reads from your Obsidian vault. Claude reads from the same vault. OpenClaw reads from the same vault. So when you give Hermes a goal grounded in your business, every other agent in the dashboard already has the same context.
Switch agents mid-workflow without re-explaining who you are.
b.
One dashboard, one tab away.
Hermes sits next to Claude, Codex, Antigravity CLI, OpenClaw, Free Claude Code, Studio, Notebook, Video. Mission Control shows the status of all of them. Goals shows the autonomous runs of any of them. Workspace shows every output across all of them.
No tab juggle. Qwen3.7-Max is now the brain behind every Hermes-driven panel.
c.
Outputs compound across the stack.
Run a Hermes Goal on Qwen3.7-Max. Output saves to Workspace. The Video agent picks up the script for a feature reel. The Notebook auto-tags the research. Claude can reference it in tomorrow's chat. The whole stack lifts.
Today's Hermes output becomes tomorrow's input across every other panel.
d.
The bill stays small.
Inside Agent OS, Hermes on Qwen3.7-Max sits next to Free Claude Code as a $0 fallback. When you don't need frontier-tier reasoning, the dashboard routes to free. When you do, you get the discount + cache + 1M context. Best-of-both.
The dashboard is what makes the discount stretch even further.
Qwen3.7-Max is the engine.
Hermes is the gearbox.
Agent OS is the chassis that turns them into a vehicle.
Thinking it?
"I'll just install Hermes alone and skip Agent OS."
You can. And in two weeks you'll be wiring everything else in anyway.
Without the shared vault, Hermes loses its memory layer. Without the Workspace, every Goal output goes into a folder you never check. Without Mission Control, you can't see when Goal Mode crashes.
The agent shines when it's plugged into the rest. Standalone, it's just another CLI. Inside Agent OS, it's a system you can ship from.
Hermes is the brain. Agent OS is the body.
✓
Members who tried Hermes standalone first all moved to the full Agent OS setup inside two weeks.
XV · the voice in your head
Three beliefs holding you back.
✕ "Closed-source frontier models are always the safest bet."
Closed models change pricing without warning, deprecate versions you depend on, and gate the best new features behind enterprise tiers.
✓ A proprietary model with open access (OpenRouter + Model Studio APIs) is the new safe bet.
You get the frontier quality with transparent pricing, a public benchmark trail, and multiple provider routing. Plus the harness layer (Hermes) is fully open.
✕ "I'll wait for the model to settle before switching."
The merge already landed. The tests already passed. The #1 app on OpenRouter is already running it in production. There's nothing to wait for.
✓ The switch is one config line — and rollback is one line back.
If anything regresses for your workflow, you point your config back at the previous model. That's it. The transition cost is functionally zero.
✕ "I don't have a workflow heavy enough to justify a frontier model."
Then you're the perfect candidate. Qwen3.7-Max's 50% off pricing + 80%+ cache discount means you can run a heavy workflow on a light budget. The frontier model becomes the daily driver, not the special-occasion one.
✓ The whole point is you stop rationing.
When the bill is small, you stop choosing between "should I do this with AI" and "is it worth it." Everything is worth it.
Don't take my word for it
258 real members already broke through these exact beliefs. Their wins — real workflows, real savings, real upgrades — are documented here.
Read the 158-page testimonials doc →