The Open Frontier Engine + LongCat-2.0.
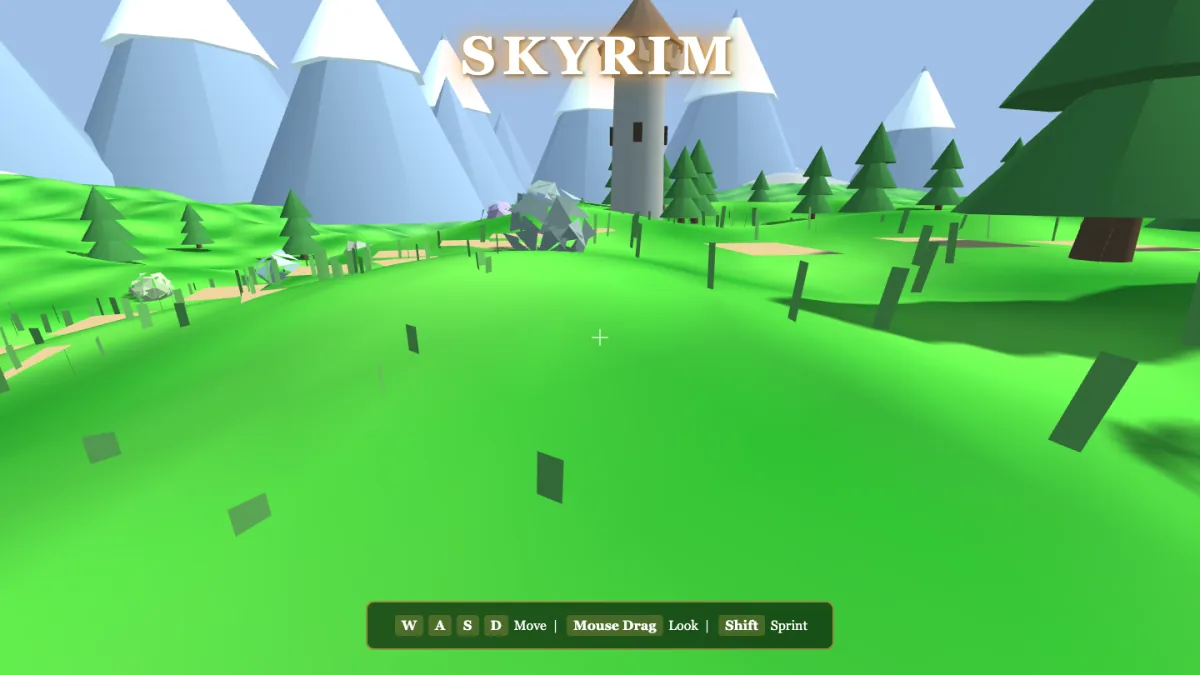
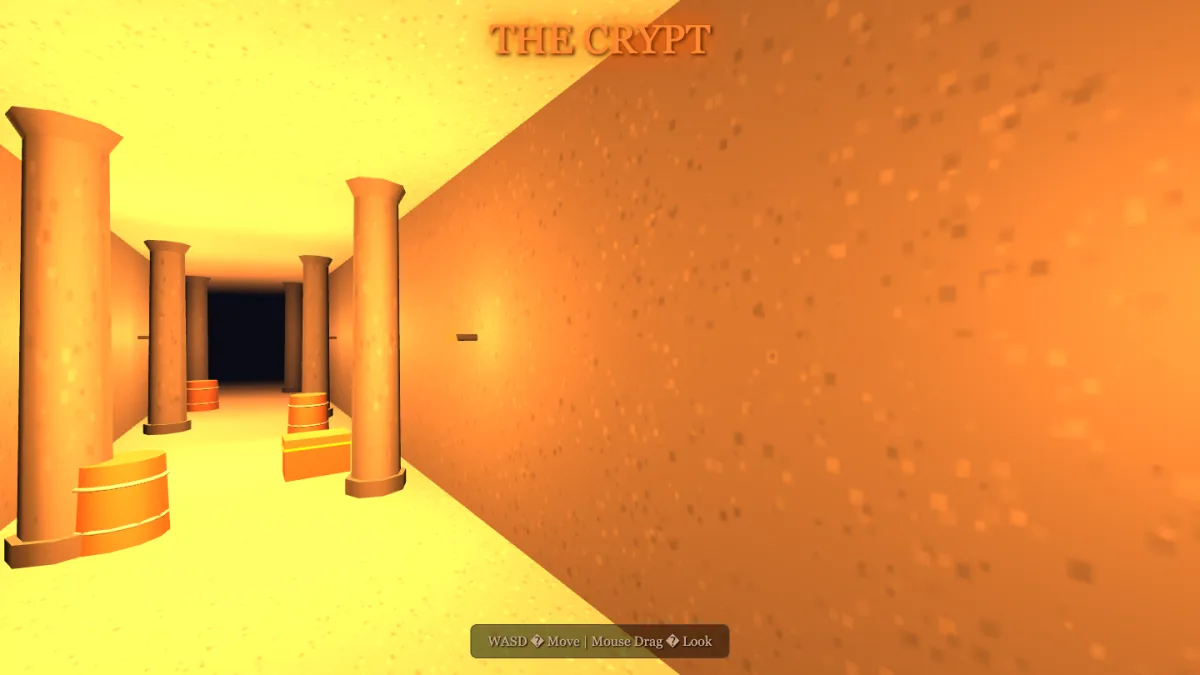
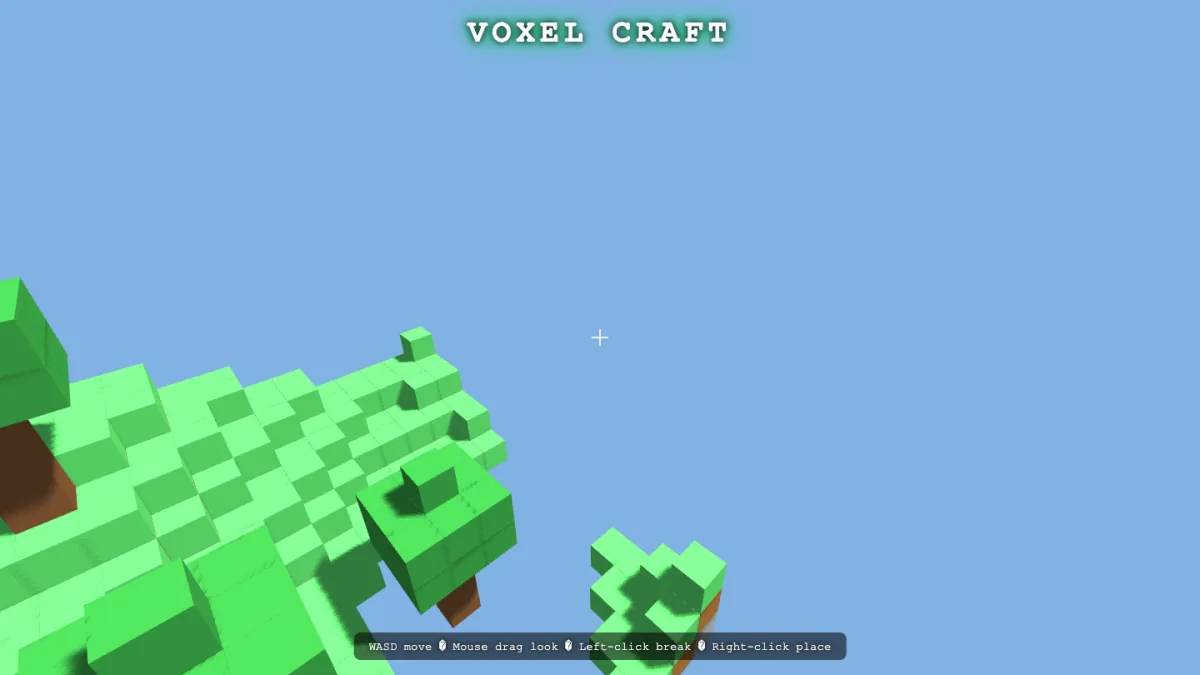
Meituan just open-sourced a 1.6-trillion-parameter model, trained on non-Nvidia chips. So I did what I always do — I gave it four one-shot game prompts. It built all four playable 3D worlds. Here's every real build, with the screenshots.

I put LongCat-2.0 on GoldieBench · 4 one-shot builds · my 0–10 rubric · render-verified
Four for four. Average 8.12/10 — a first appearance that lands it near the top of the board, above Opus 4.8's average on these tasks. Every score is a build I watched render AND drove with WASD + mouse.
1.6T
parameters (~48B active/token)
4 / 4
playable builds, one-shot
$0
open weights · free to run