Local AI · tested + benchmarked on my Mac

I tested the viral "Qwable 27B Coder" locally. Here's the truth.
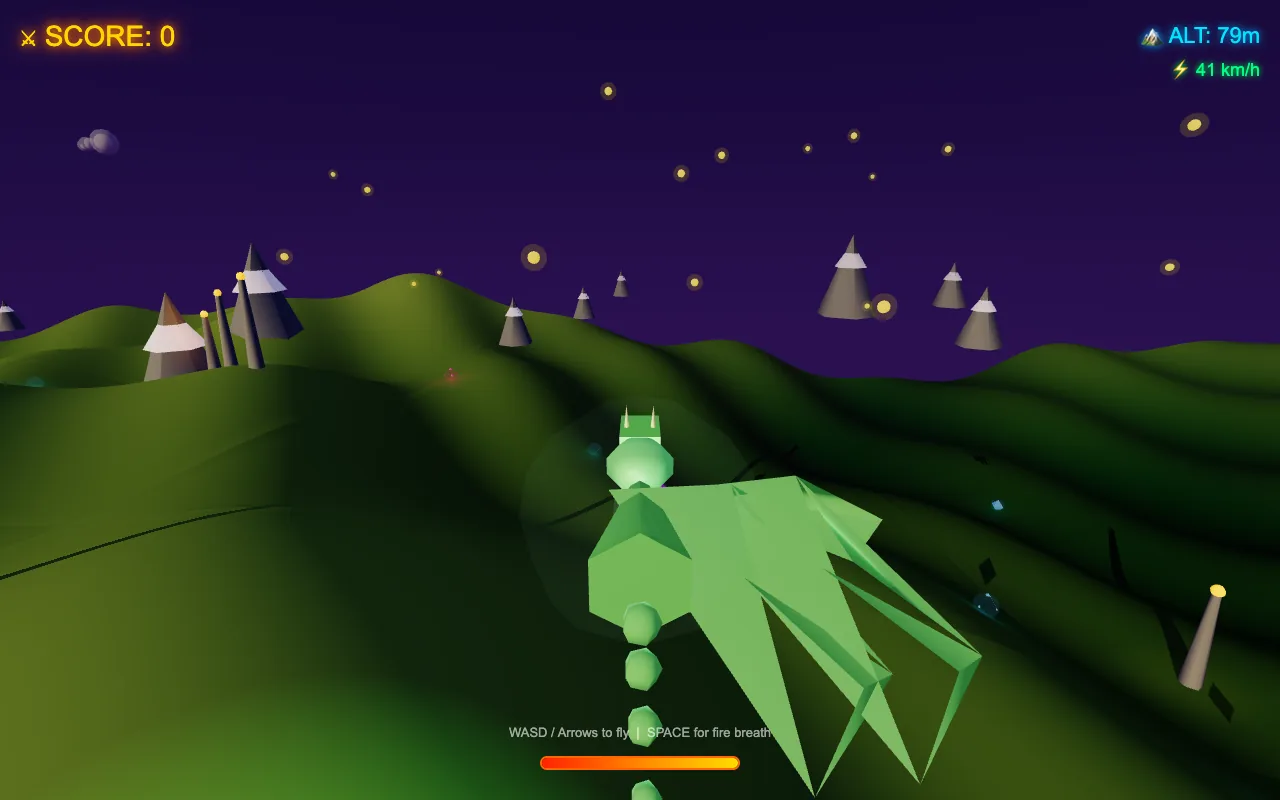
It's the model its own author calls a hype cautionary tale — 10 training examples, three minutes of training. Ollama can't even run it. So I ran it on Apple MLX, benchmarked it, and had it build games. What came out surprised me.
27Bparameters (Qwen3.6)
~18tokens/sec · MLX · M4 Max
8.3top GoldieBench build
$0100% local