Same five prompts, three frontier coders, one shot each — single HTML file, no follow-ups — all run through Agent OS. Then screenshotted and embedded live, side by side. You play them yourself.
The five tests: a Temple-Run voxel runner (Three.js) · an inner-solar-system / near-Earth-objects orbit visualizer · a liquid-in-a-bowl fluid sim · an "Introducing Nova 1" landing page · a juicy neon arcade game. Each model got the identical prompt.
The scoreboard
How they stacked up. My honest scoring.
Scored on whether it ran, how close it hit the brief, and how good it looked — out of 10, averaged across all five one-shot builds.
Overall — Agent OS one-shot average
Real scores from these 5 head-to-head builds (not a public benchmark).
GLM-5.2
8.5
Opus 4.8
8.4
Qwen 3.7
7.5
The short version: GLM-5.2 and Opus 4.8 are neck-and-neck — GLM on raw visual flair, Opus on accuracy and game-feel. Qwen3.7-Max ships clean, working builds but landed a step behind on dazzle here — which is the twist, because Qwen has the best benchmark scores of the three (more on that below).
✦
Test 1 · voxel runner
Temple-Run voxel runner (Three.js).
One shot: an endless third-person voxel runner through a procedural city — dodge blocks, grab coins, speed ramps up.
GLM built the densest, most colourful city (windowed skyscrapers + speed/coins HUD). Opus ran the furthest with the cleanest motion. Qwen's is atmospheric — a foggy tunnel of buildings — but more muted and it crashes quicker.
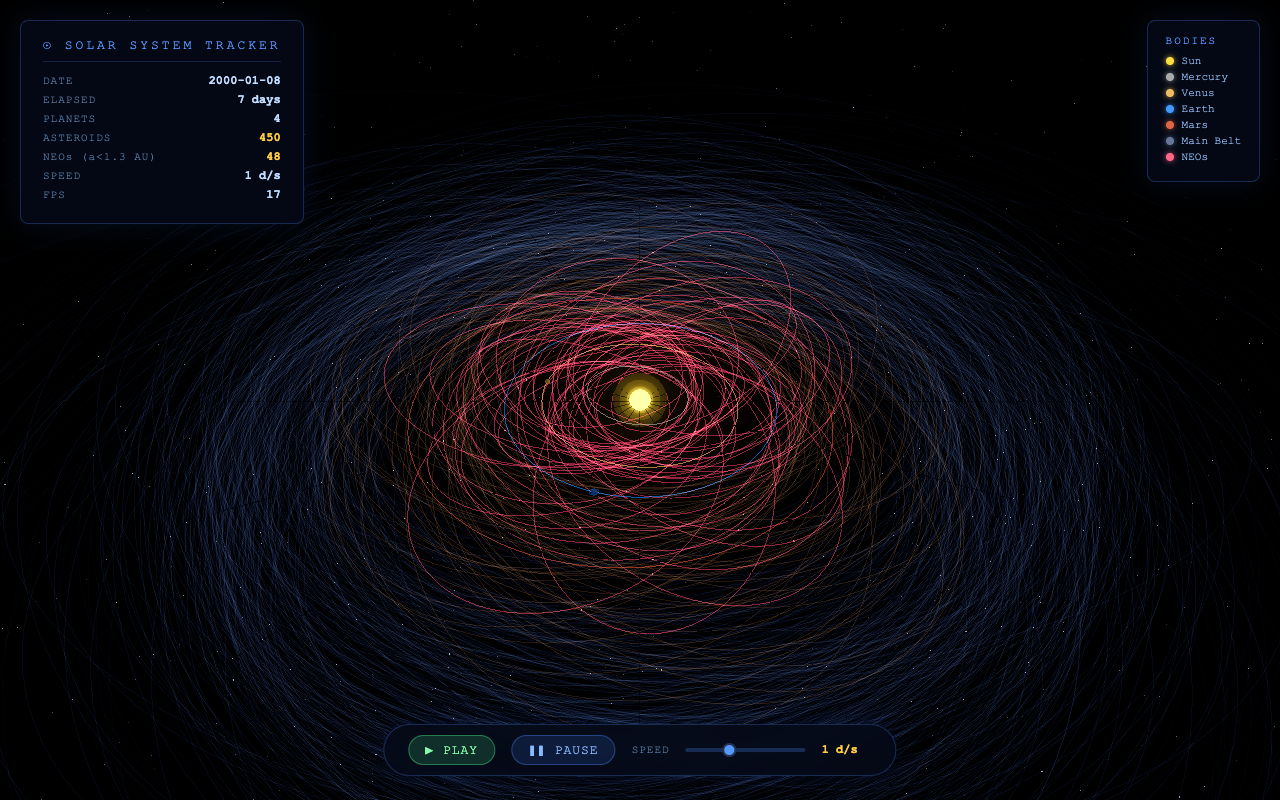
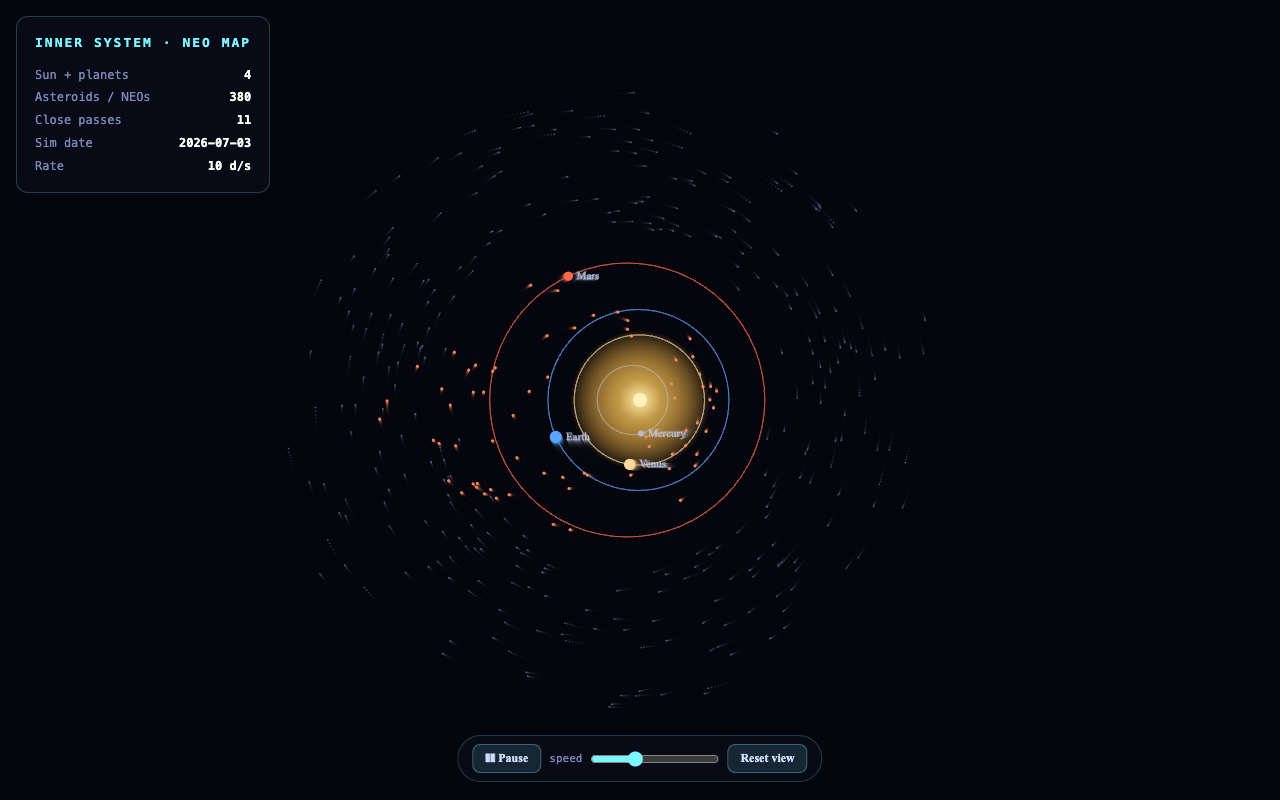
Test 2 · orbit visualizer
Inner-system orbit map.
One shot: the inner solar system + a few hundred near-Earth-object orbits, with play/pause, speed, and a data HUD.
Opus nailed the brief — distinct labelled planet orbits, a real NEO panel, a sim clock. GLM went dramatic with a glowing nebula swirl (gorgeous, but more galaxy than orbit map). Qwen drew a dense, busy orbital swarm — structurally orbit-like but dimmer and harder to read.
Test 3 · fluid sim
Liquid in a bowl.
One shot: thousands of particles sloshing in a round bowl you tilt with the mouse, soft glowing metaball look.
▶ all three live — move your mouse over a panel to tilt the bowl
GLM-5.2
9
winner · best liquid
OPUS 4.8
7
QWEN 3.7
7
GLM filled the bowl with glowing liquid that genuinely sloshes — the most convincing of the three. Opus's particles glowed but clumped to the centre, and Qwen's is a solid working sim but reads thinner. Play them and tilt — GLM's is the one that feels like fluid.
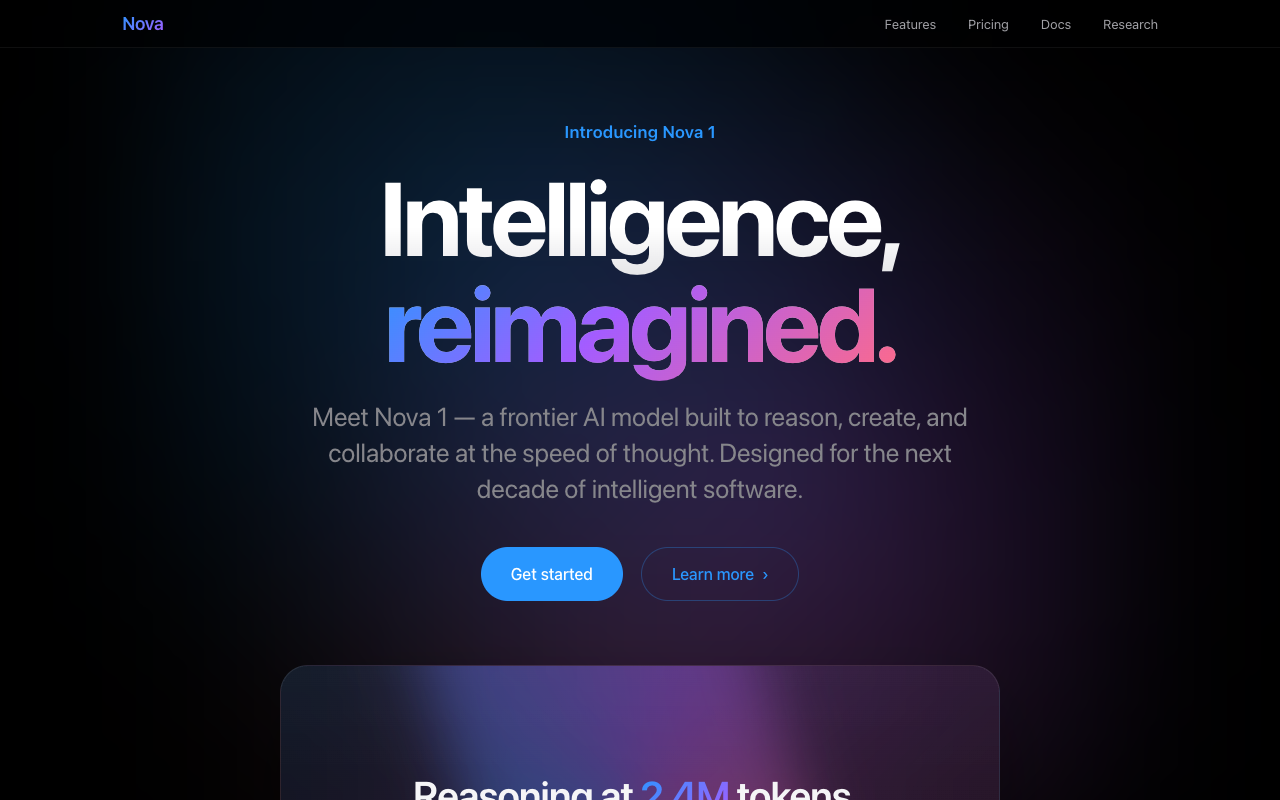
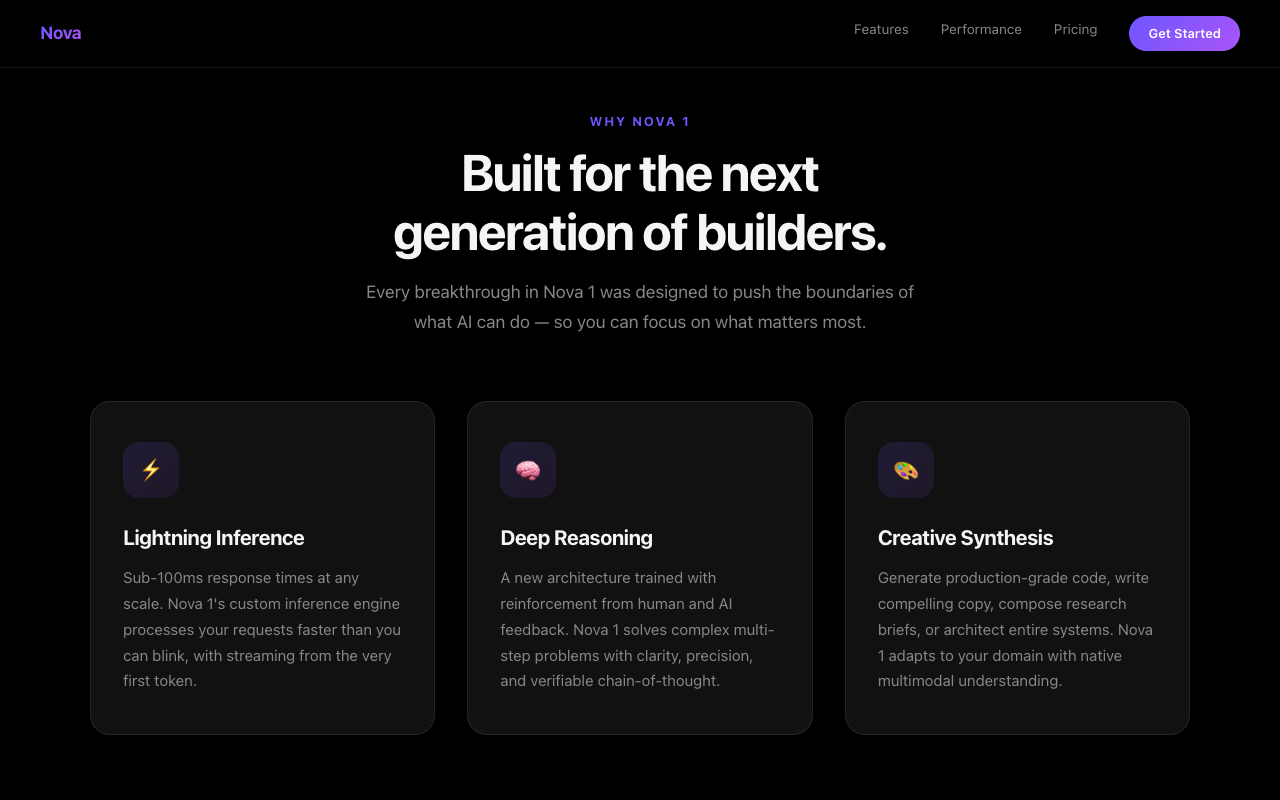
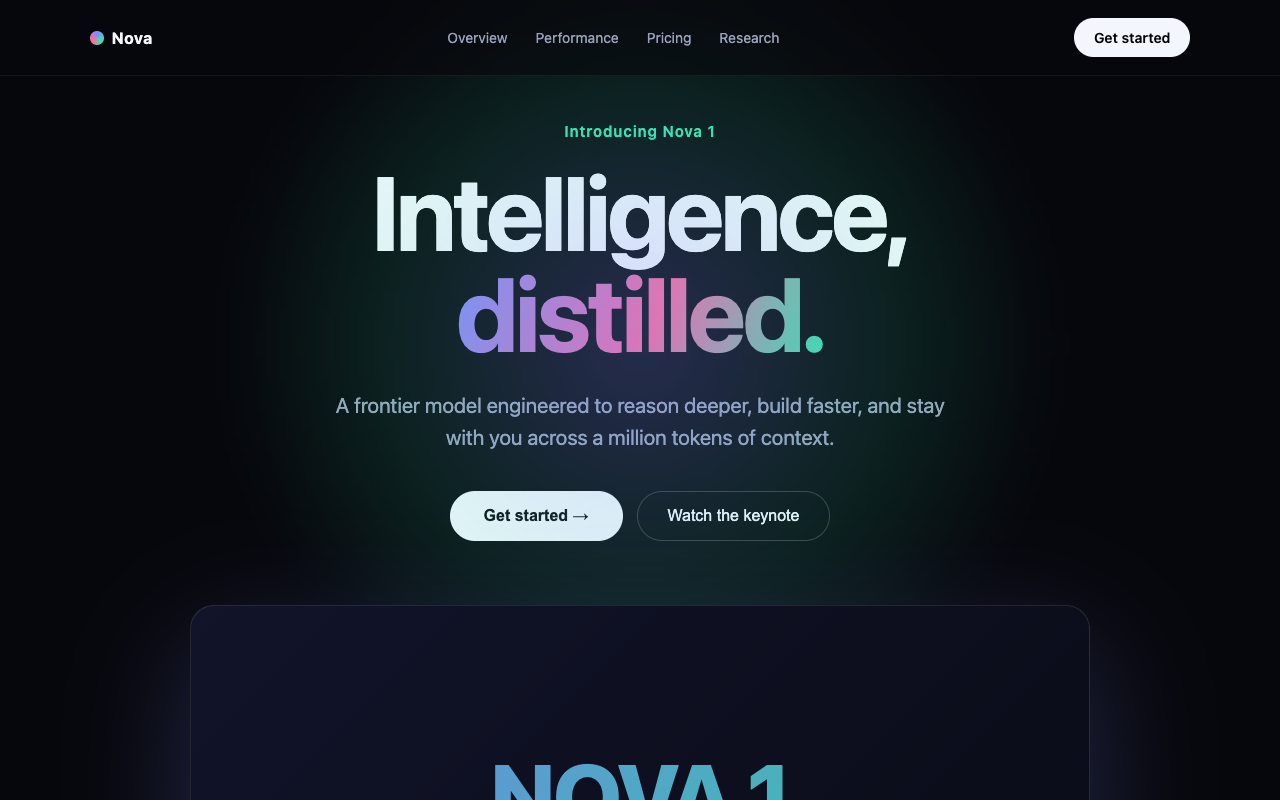
Test 4 · landing page
"Introducing Nova 1" landing page.
One shot: a premium Apple-keynote-style launch page for a fictional AI model — hero, features, pricing, scroll reveals.
GLM and Opus both produced premium gradient "Intelligence, reimagined / distilled" keynote heroes — basically a tie. Qwen's is clean and well-built (proper nav + three feature cards) but the headline ("Built for the next generation of builders") lands flatter than the gradient heroes.
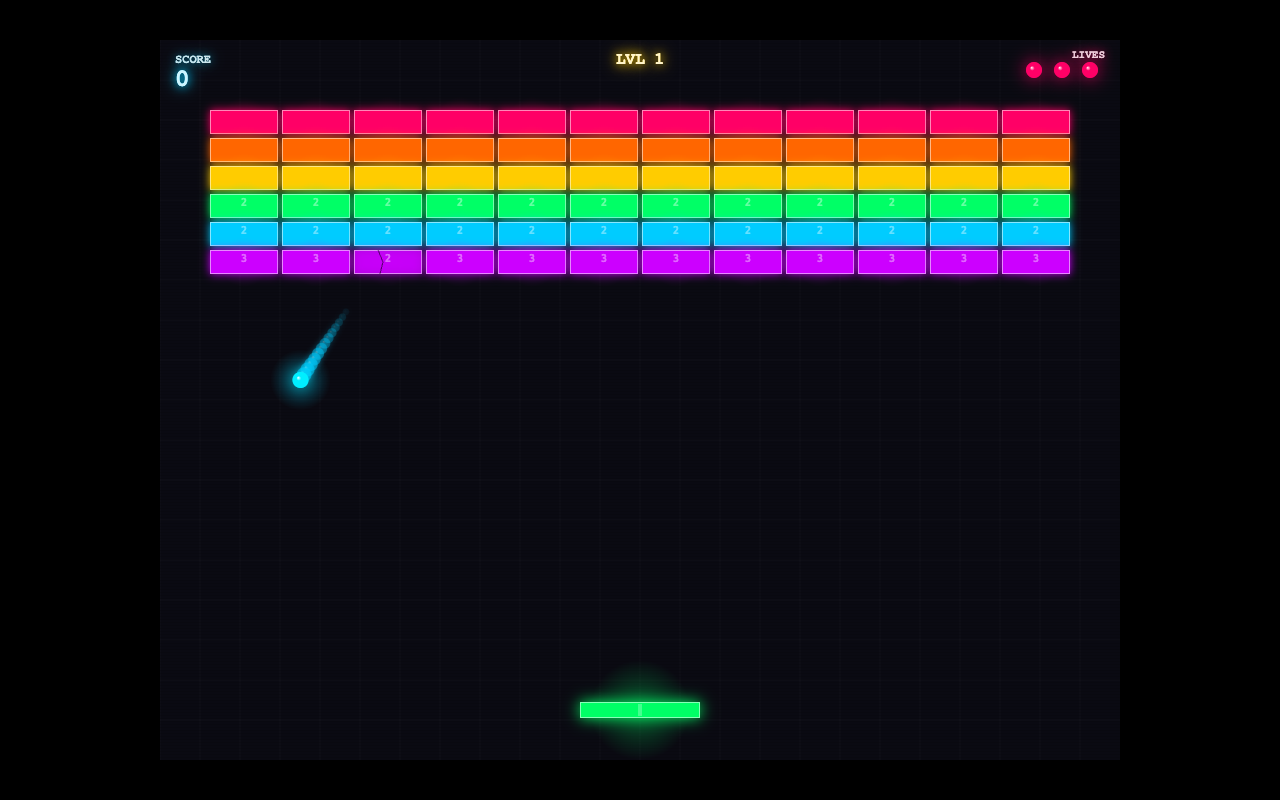
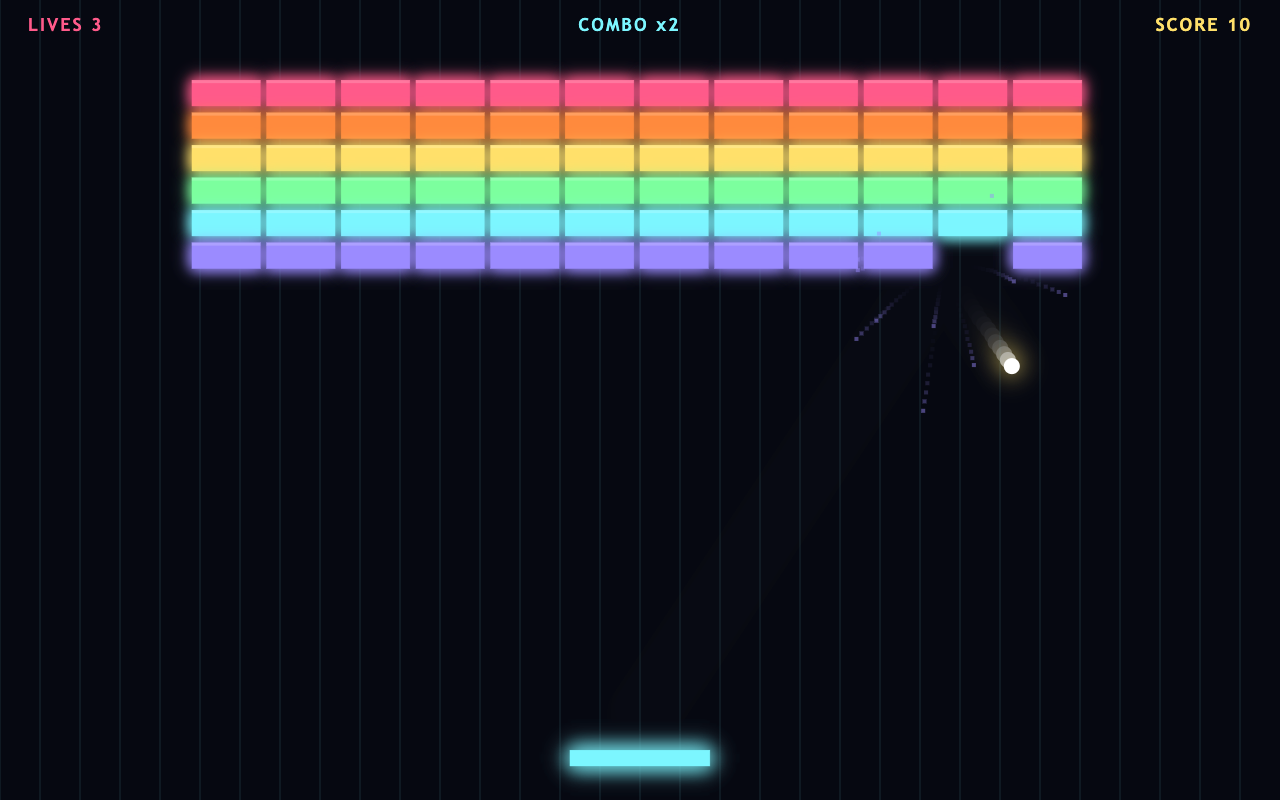
Test 5 · arcade game
Juicy neon arcade game.
One shot: a neon arcade game with screen shake, particle explosions, a combo multiplier, sound, and start + game-over screens.
The closest test. All three shipped a real, juicy game. Opus's breakout had the most game-feel (particle bursts + live combo). Qwen's neon breakout is clean and vibrant. GLM went its own way with fullscreen asteroids. Genuinely hard to separate.
✦
The benchmark twist
But on the benchmarks… Qwen wins.
Here's the interesting part. On these five one-shot visual builds, Qwen finished third. But on the published coding benchmarks, Qwen3.7-Max is the strongest of the three — Alibaba reports 80.4% on SWE-bench Verified and 60.6% on SWE-bench Pro, beating Opus 4.7 on agentic coding (Terminal-Bench, MCP-Atlas). GLM-5.2, meanwhile, shipped with no scorecard at all.
SWE-bench Pro — vendor-reported
The one benchmark with a number for (near-)current versions of all three. Vendor-reported scaffold scores — directional, not Scale's independent leaderboard.
Opus 4.8
69.2%
Qwen3.7-Max
60.6%
GLM-5.1 (5.2 pending)
58.4%
And on SWE-bench Verified, Qwen3.7-Max's 80.4% sits right up with the leaders (Opus ~80.9, GPT-5.2 ~80.0). So the lesson is the usual one: benchmarks measure agentic problem-solving; they don't measure whether a one-shot demo looks gorgeous. Qwen reasons brilliantly — its builds here were just a touch plainer to the eye.
Read this before you quote any of it ↓
The 5-test scoreboard is real — my own builds, my own scoring — but it's 5 prompts and one person's eye, not a statistical benchmark.
It rewards "ran + hit the brief + looked good" in one shot. A second prompt, or a coding task instead of a visual demo, would reshuffle the order — and the benchmarks suggest Qwen would climb.
The SWE-bench bars are vendor-reported scaffold numbers (they run higher than Scale's independent leaderboard), and GLM is 5.1 — z.ai hasn't published any official GLM-5.2 coding scores yet.
Different day, different prompts, different order. This is a snapshot, not a verdict.
Run your own
Want all three coders in one place?
GLM-5.2, Qwen 3.7 and Claude all run inside the Agent OS — one dashboard, one workspace, builds previewing live. Set it up, run your own head-to-heads, keep the winners.
The AI Profit Boardroom is where the actual Agent OS lives — the templates, the prompts, the daily rooms, the weekly walkthroughs. Same builds you read about here, taught hands-on inside.