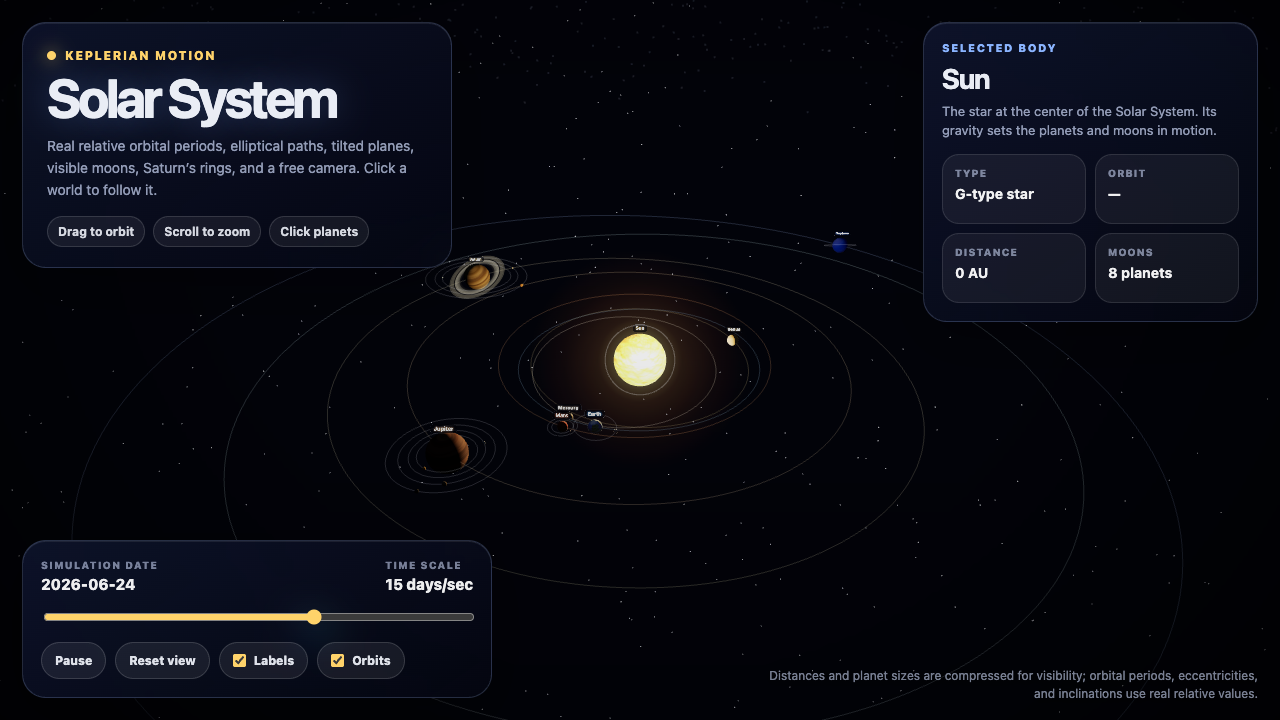
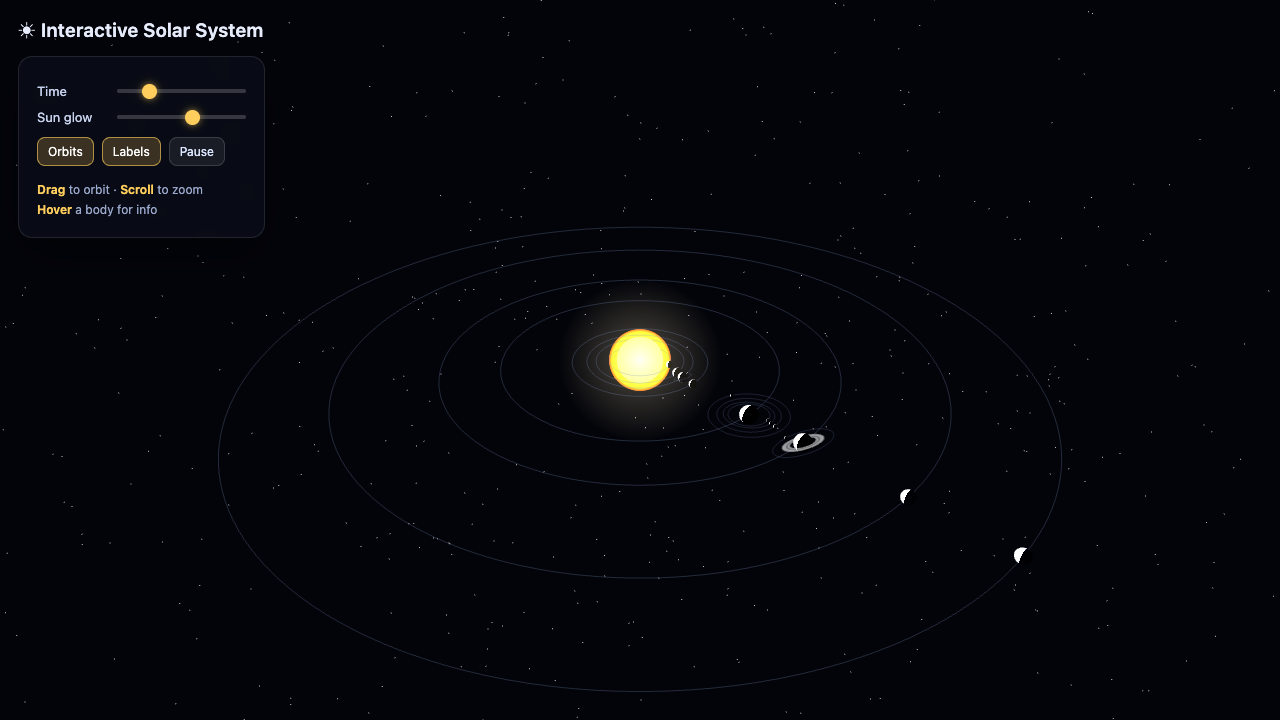
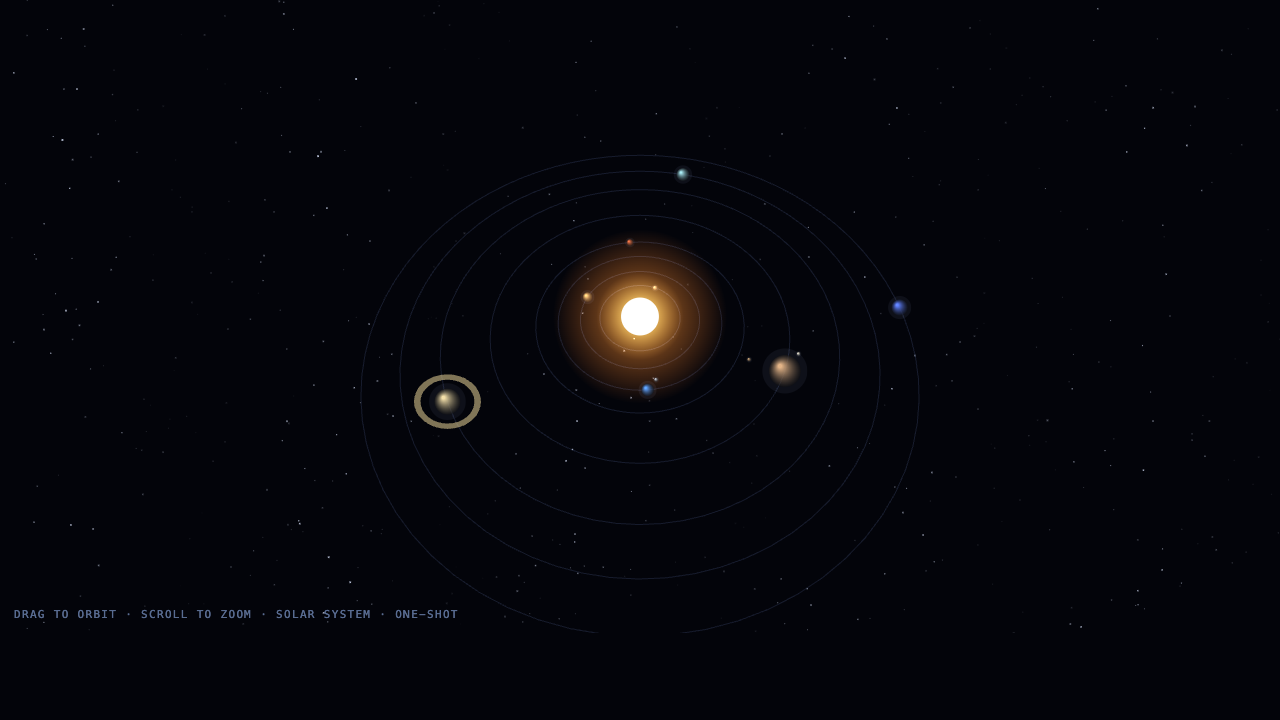
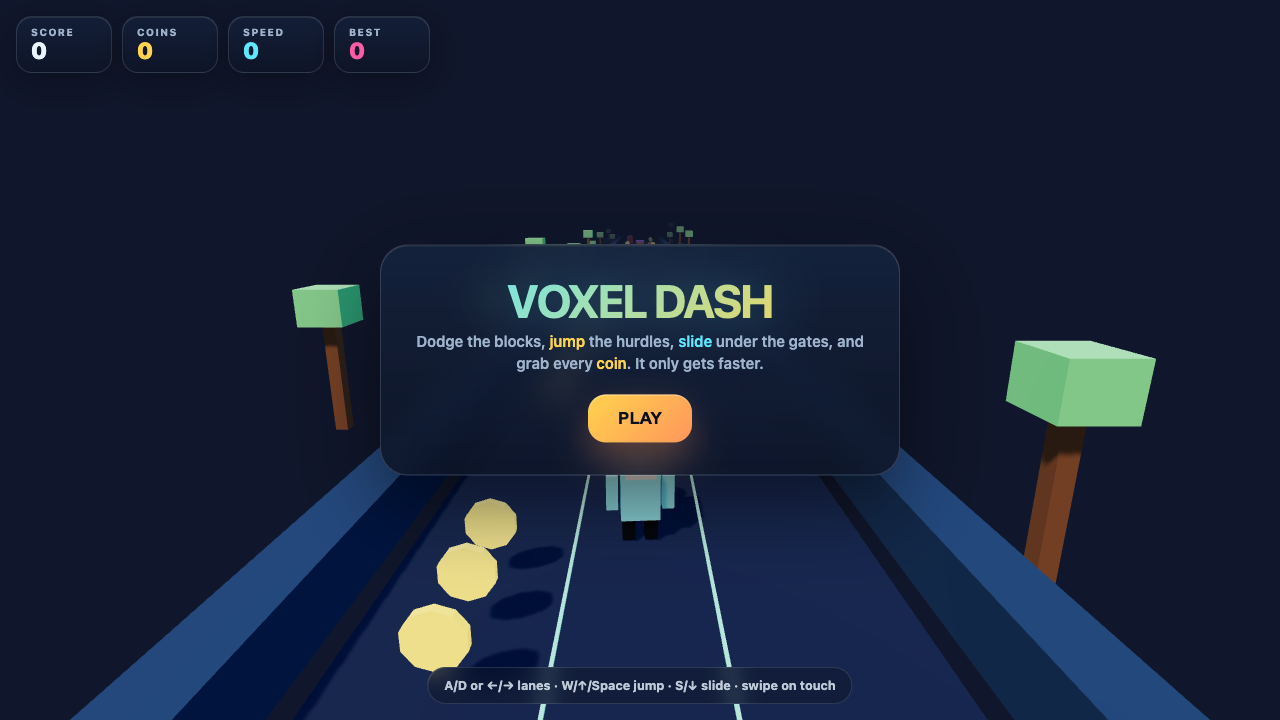
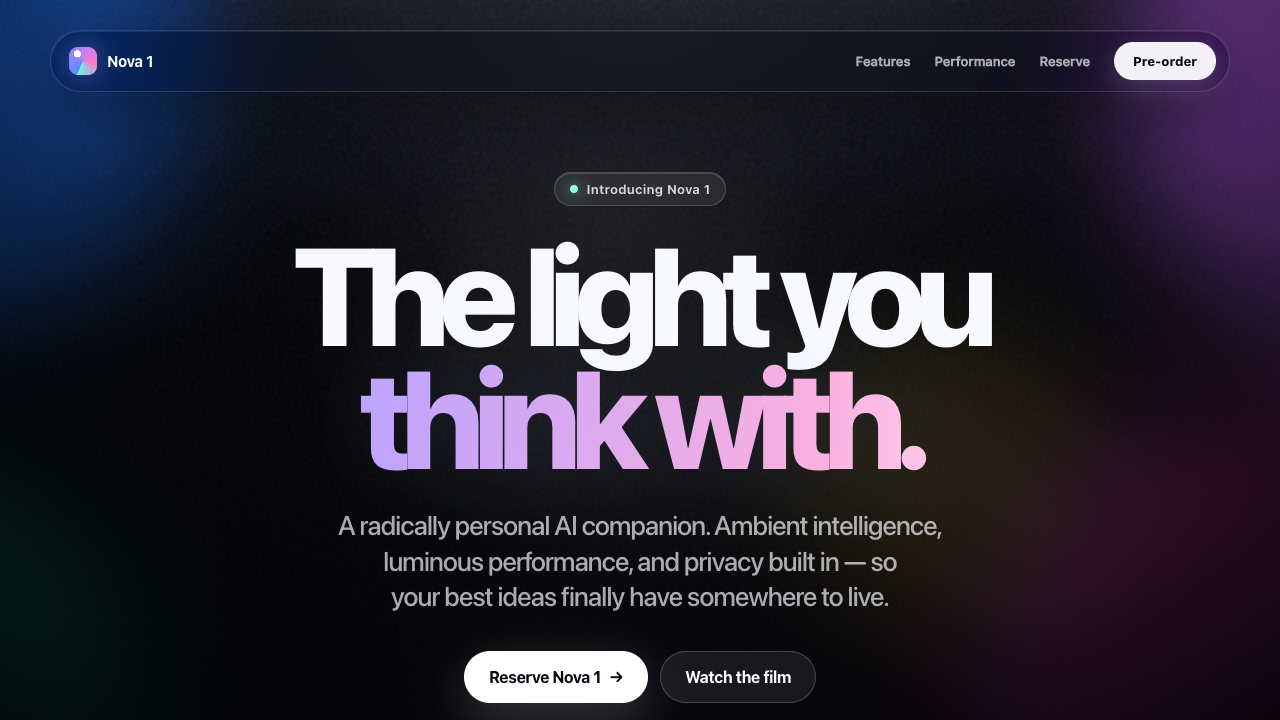
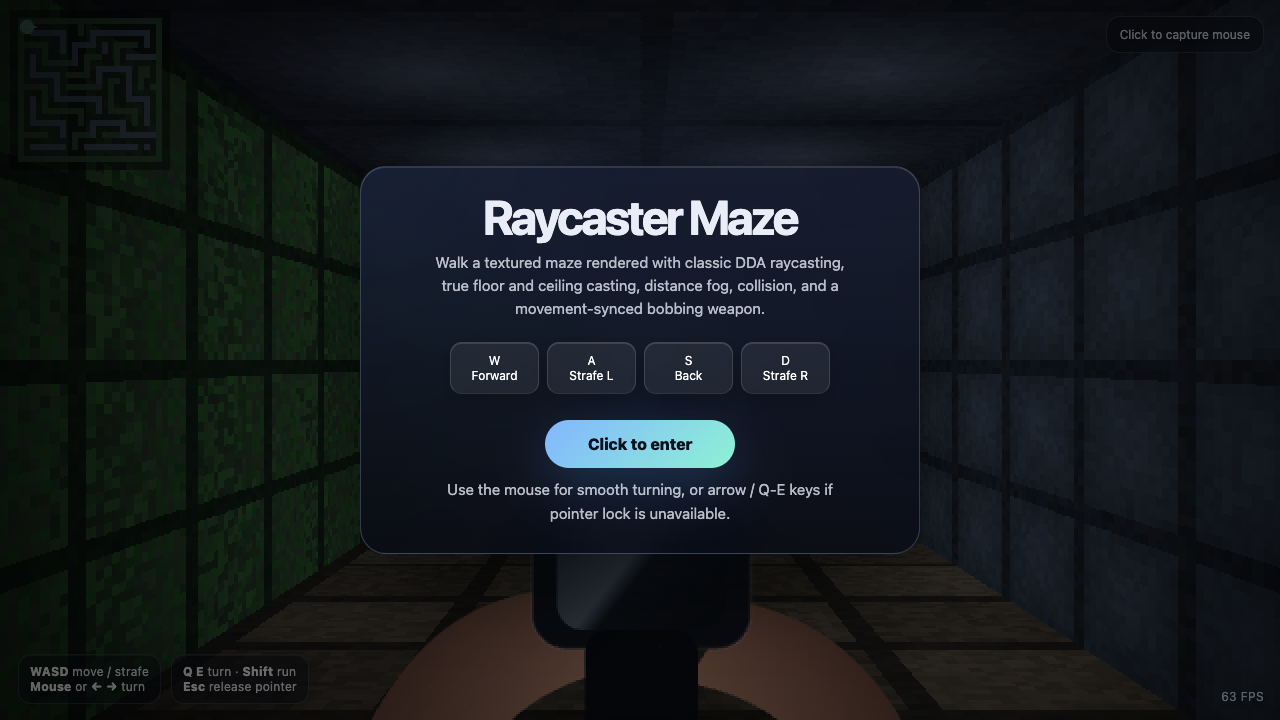
The honest part
What didn't work as well.
I'm not going to pretend all 42 builds were flawless. They weren't. Here's exactly where Fugu Ultra struggled — because the rough edges are as useful to know as the wins.
About a third needed a human to confirm they play.
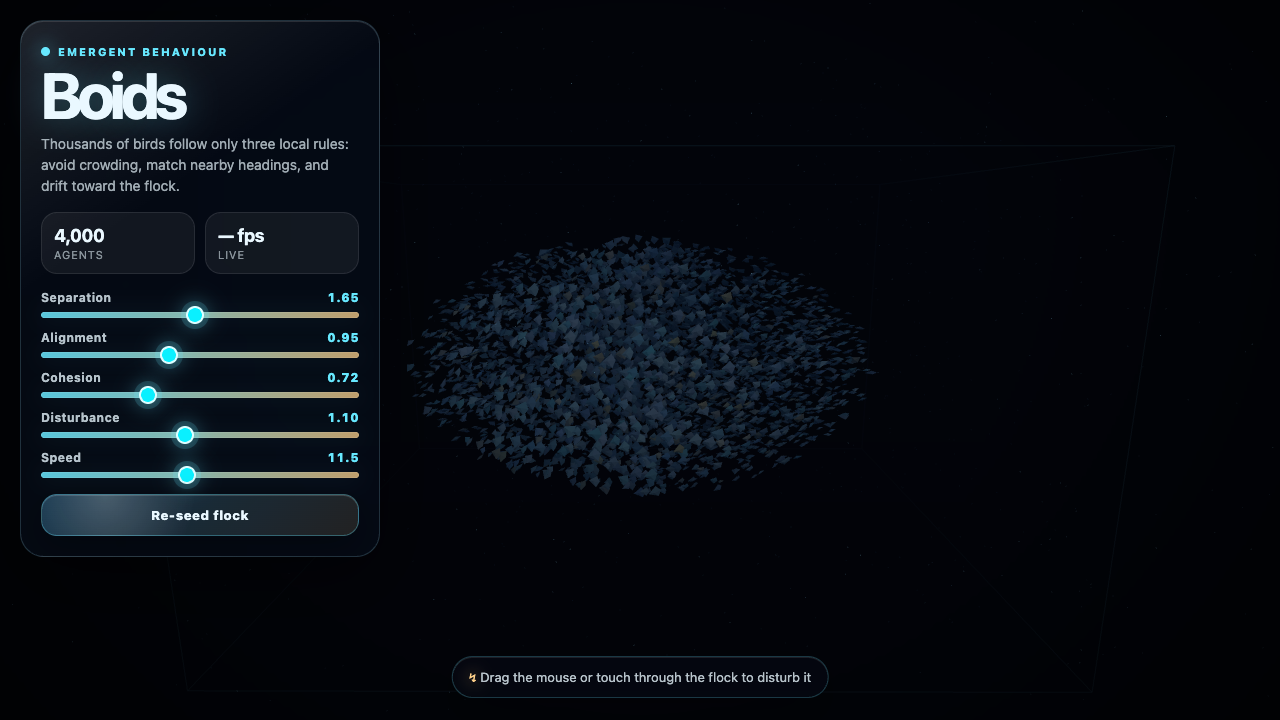
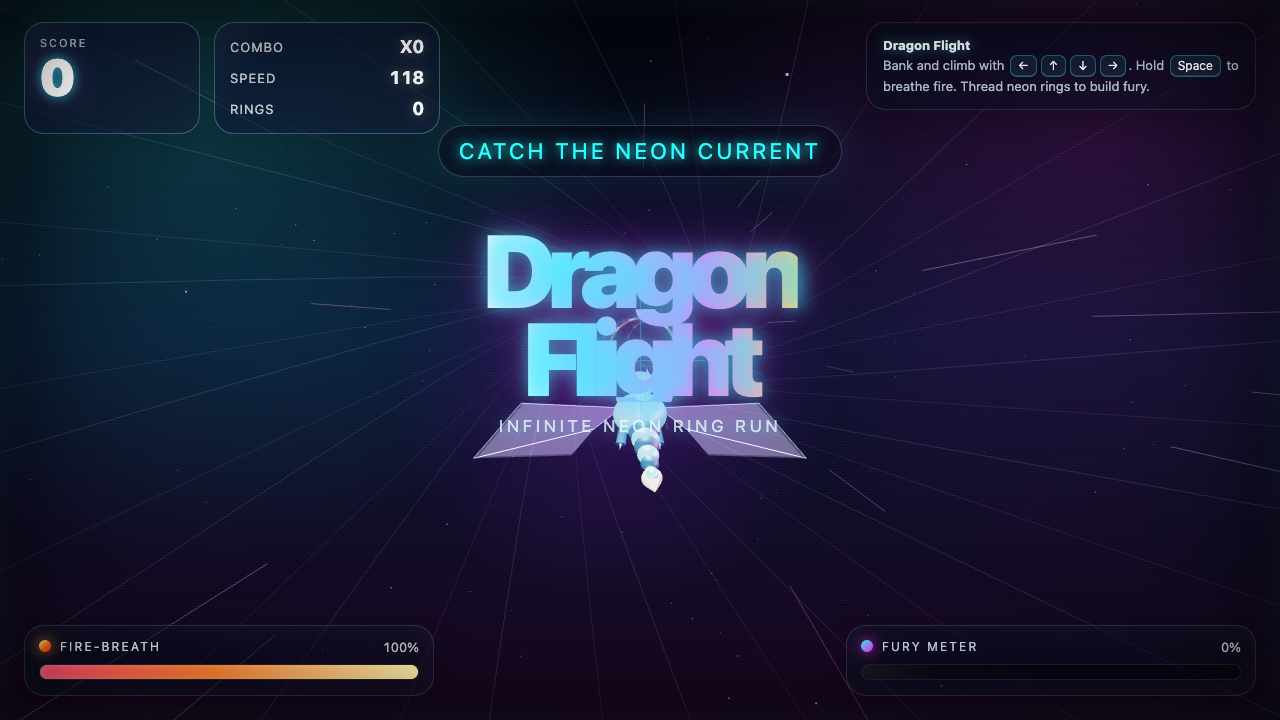
I smoke-test every build in a real headless browser — click the screen, press the keys, check the pixels actually change. Roughly 14 of the 42 Fugu Ultra builds came back as "maybe." They're structurally complete — closed tags, a real game loop, input handlers, a fully rendered scene — but my automated test couldn't fully drive them. These were pointer-lock FPS games (doom, skyrim, crypt, dogfight) and click-drag games (pool, neonblaster, fluid) where a generic click-plus-WASD can't trigger the specific controls. I scored those 6.5–7.0 and flagged them for manual checking instead of claiming they work. Not broken — just unverified by a robot.
It's slow, and the two heaviest prompts timed out — four times each.
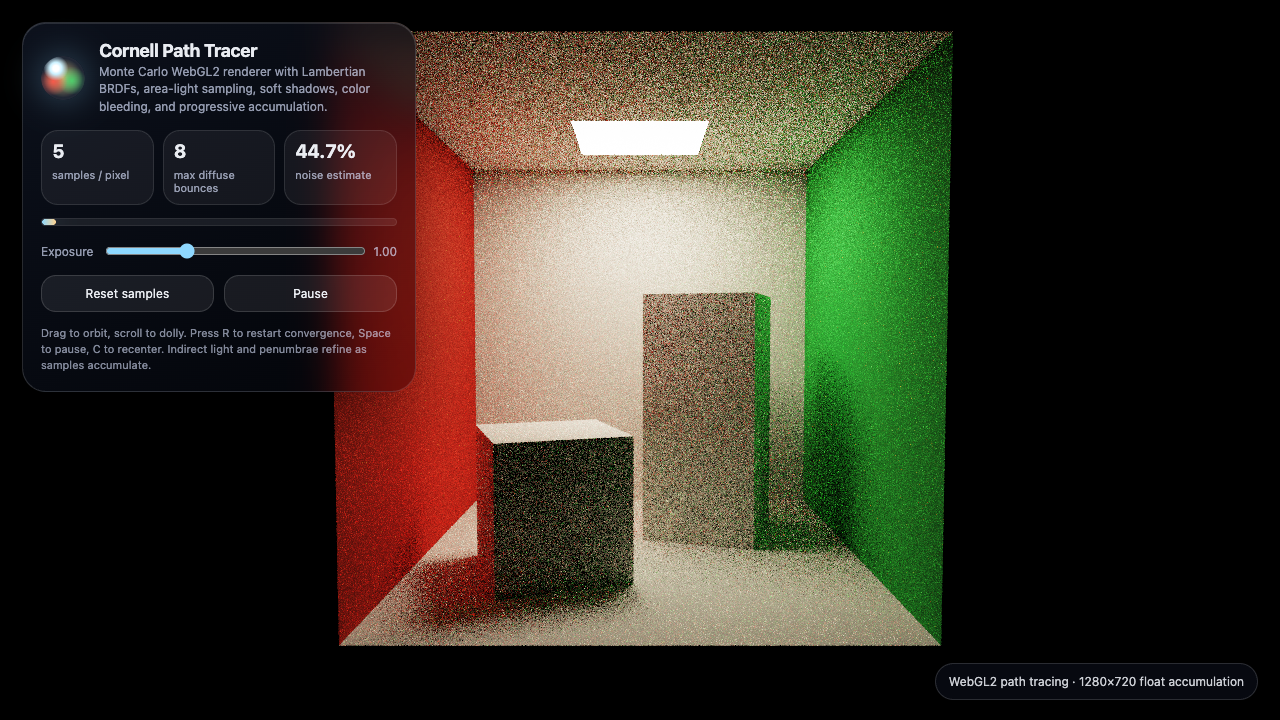
Fugu Ultra is a panel ensemble, so it's not fast — roughly 15 minutes per build. The two most complex prompts (a full Doom-style FPS and a pseudo-3D OutRun racer) blew past my 40-minute cap on four straight attempts before finally landing on a direct retry with a longer ceiling — 16 and 19 minutes respectively. Frontier quality, but you wait for it.
Thinking it?
"If it times out, the API must be broken."
It wasn't broken — it was busy. The first run used the wrong endpoint and a 16K token cap, and half my densest builds got cut off mid-file with no closing tags. The fix was switching to Sakana's documented Responses API with a 48K output budget. After that, every build came back complete. If you're calling Fugu yourself: use the Responses API and give it room. That one change fixed the truncation entirely.
The cheaper Mini variant couldn't finish the hardest prompts at all.
Sakana also ships Fugu Mini — a faster, single-model version. I ran it through the same 42. It only completed 37. On the five heaviest prompts (the dungeon crawler, billiards, a Minecraft-style sandbox, the open-world RPG, a bullet-hell shooter) it returned empty every time — it burns its whole token budget on reasoning before it writes a line. Ultra's panel finished all 42. That gap is the clearest argument for paying for Ultra over Mini: the panel completes the work the single model can't.