I gave all three frontier coders the exact same fourteen prompts — one shot, single HTML file, no follow-ups — straight through Agent OS, then put every build side by side. The headline is five hard, interactive builds — a game engine, a shooter, a city flythrough, a racer, a space sim — the kind of thing where one prompt shouldn't be enough. Then nine more. Same test, three models, you decide.
The deep five: a first-person raycaster FPS · a DOOM-style shooter with enemies · a neon-city flythrough · an OutRun racer · a solar-system sim. Plus nine: a Temple-Run voxel runner · an orbit visualizer · a fluid sim · an "Introducing Nova 1" landing page · a neon arcade game · a spiral galaxy · an Interstellar black hole · a Mandelbrot zoom · a Tron terrain. Each model got the identical prompt.
The highlight reel · one prompt each
What one shot actually built.
No cherry-picking — the standout builds from the fourteen below, each shown in the winner's version. Five you can play, four pure spectacle. Click any one to run it live.
▶ each tile opens the live build · the full head-to-heads (all three models) are further down
The drop · @Zai_org
z.ai ships GLM-5.2.
The official launch — "frontier intelligence, open weights," a 1M-context window and two reasoning efforts (max / high), at the same price as 5.1. This is the exact model in the green column all the way down this page.
Introducing GLM-5.2: Frontier Intelligence, Open Weights.
Design Arena pits models head-to-head on look-and-feel and front-end craft — the same instinct the visual builds above test. Crowd-judged, blind. See where GLM-5.2 lands →
LMArena is the community standard — thousands of people blind-voting one model against another. Useful external signal, even if it isn't a pure coding benchmark (which, as I get into lower down, still doesn't cleanly exist for these exact versions).
Open weights, delivered: GLM-5.2 is a pull away from running locally through Ollama. That's the whole point of "open" — you don't have to take anyone's benchmark on faith, you can run it yourself.
Across all fourteen builds, scored on whether it ran, how close it hit the brief, and how good it looked. Out of 10, averaged.
Overall — Agent OS one-shot average
Real scores from these 14 head-to-head builds (not a public benchmark).
Opus 4.8
8.4
GLM-5.2
8.3
Kimi K2.7
7.3
The short version: across all fourteen, Opus 4.8 is the most consistent — no weak build — and edges it overall. GLM-5.2 ships the most polished presentation (gorgeous title screens, the best neon city, the prettiest synthwave terrain) and ties Opus for flair, but face-planted on the raycaster. Kimi K2.7 is the surprise: right in the mix on the interactive builds — its DOOM and raycaster are textbook — and only trails because it plays plainest on the abstract visual prompts.
The five interactive builds are the real test, so they're up first. Then the nine visual head-to-heads — and a full-screen Kimi solo gallery (aurora, a neon wormhole, lava lamp, the Matrix and more). Start with the deep end ↓
✦
The deep end · five interactive builds
The hard round — stuff you actually play.
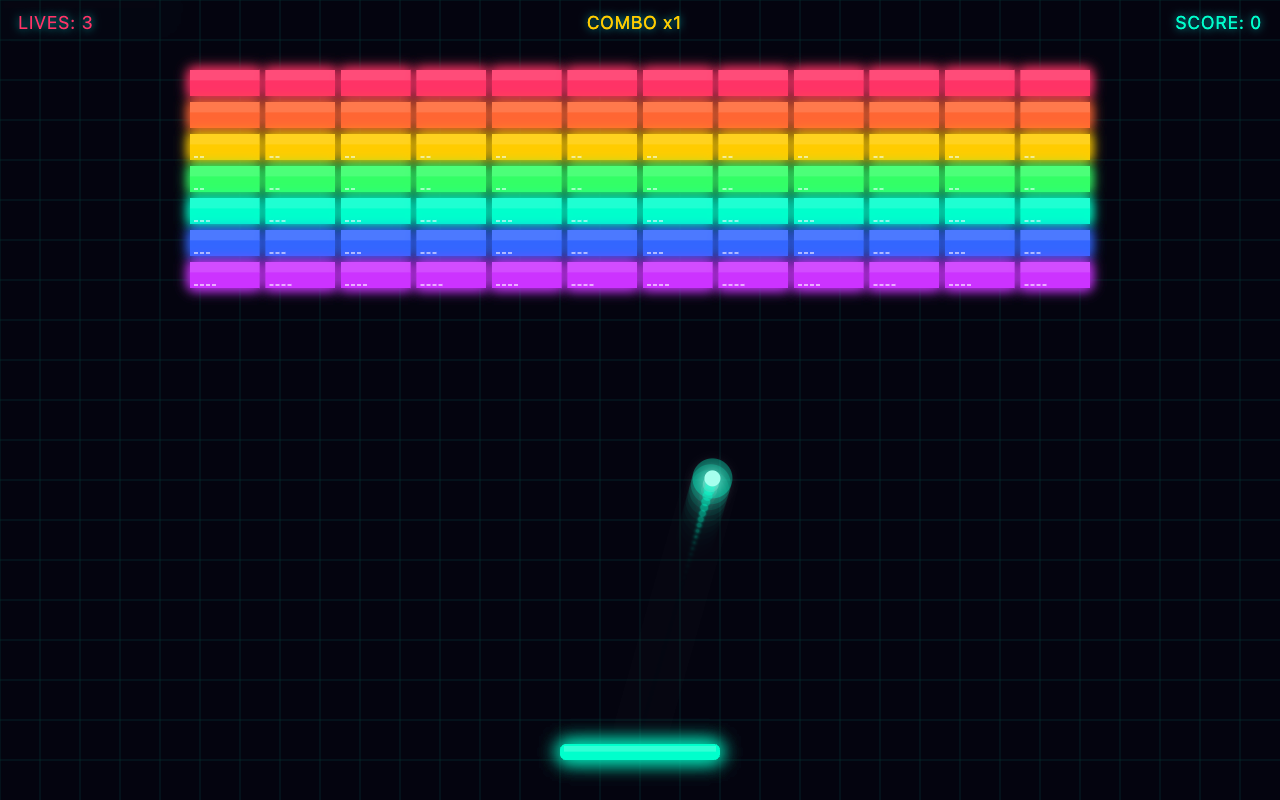
Pretty pictures are easy. These five are the real test: a game engine you walk through, a shooter with enemies, a city flythrough, an arcade racer and a solar-system sim. Recognisable, interactive, and the kind of build where one shot should be impossible. Identical prompt to each model — click any panel and play.
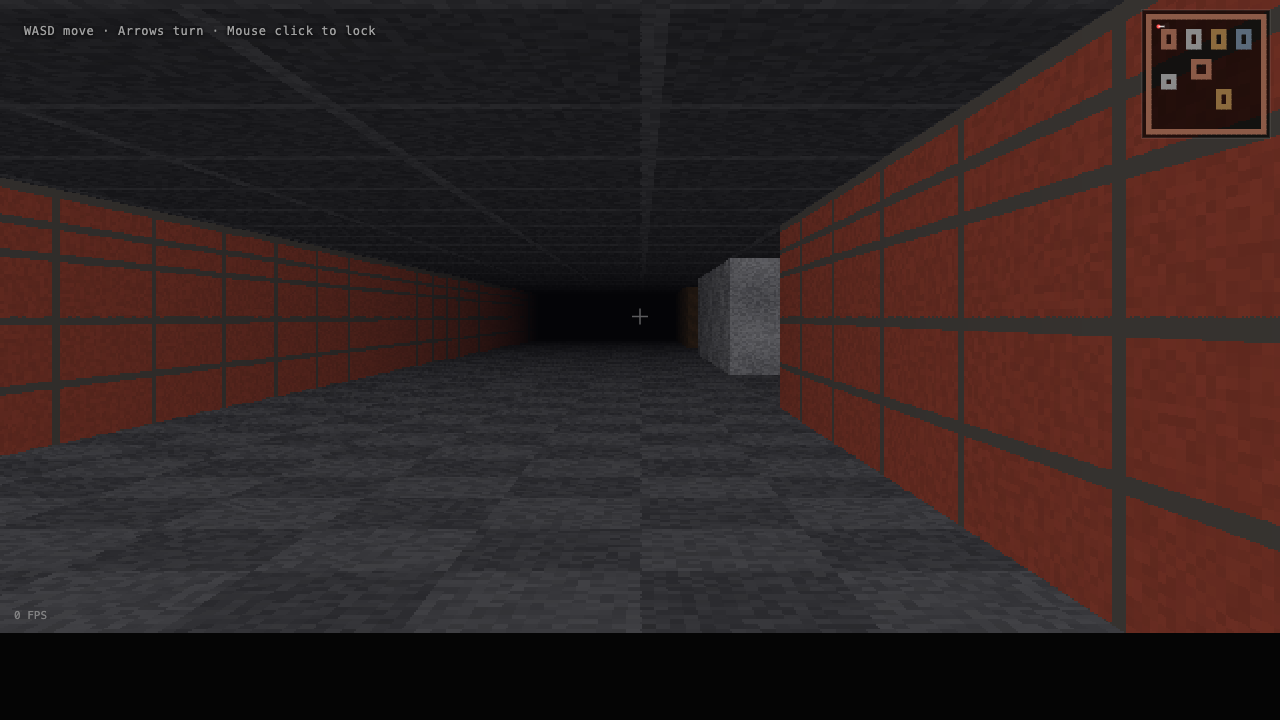
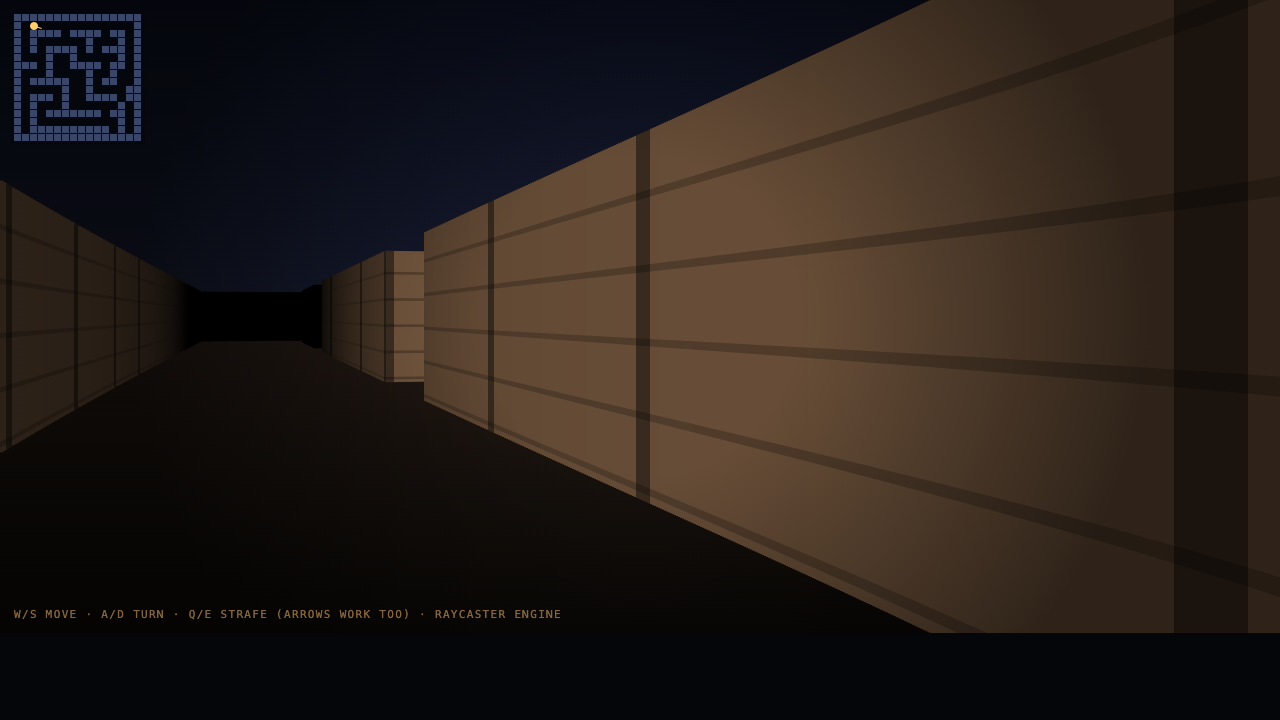
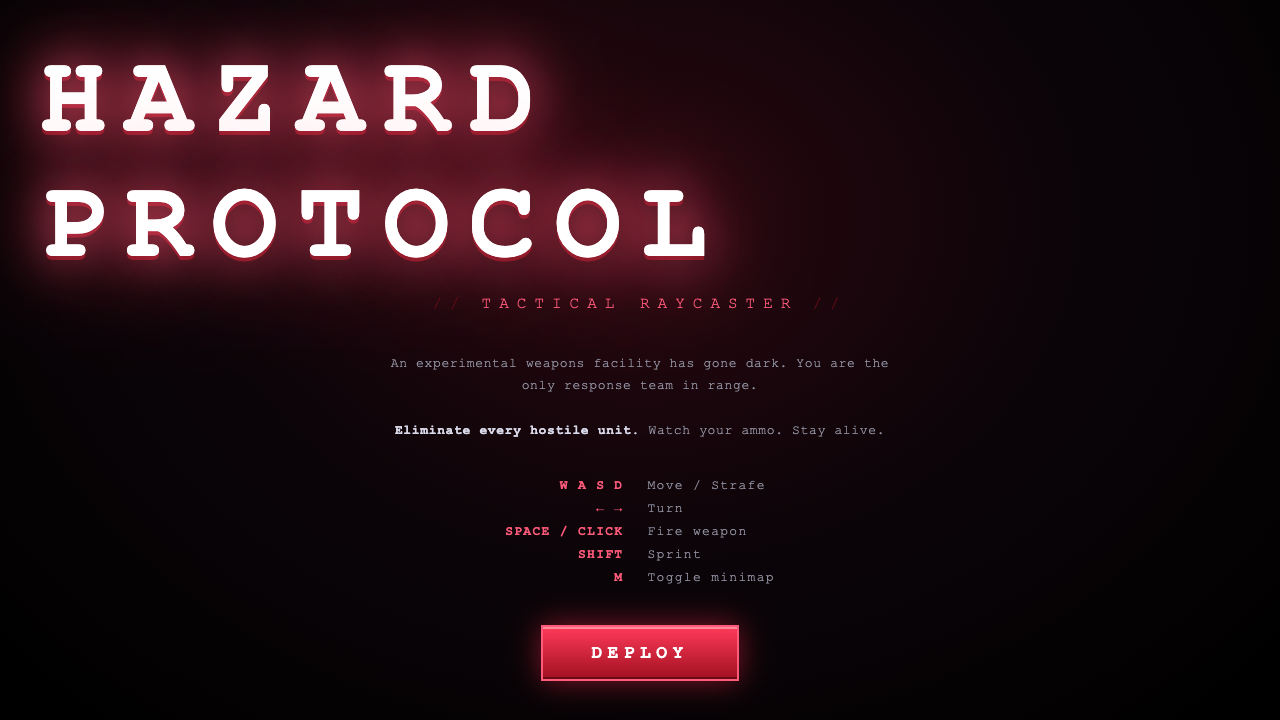
Deep build · Raycaster FPS
Walk through a maze you raycast.
A first-person raycaster engine — walk a textured maze with WASD, floor and ceiling, distance fog, wall collision, a minimap. A whole engine in one file.
▶ all three live — click a panel and walk (WASD) · scroll on for the next build
KIMI K2.7
8.5
winner · cleanest
OPUS 4.8
8
GLM-5.2
6.5
Kimi nailed it — brick walls, a checkered floor, a clean minimap, textbook Wolfenstein, runs clean out of the box. Opus's is close and more atmospheric: warm fog and a vignette down a stone corridor (A/D to turn, W/S to move). GLM's engine is genuinely good — brick and mossy-stone walls, fog, a minimap — but its one-shot spawned the player buried inside a wall, dead on arrival; I nudged the start one cell so you can actually walk it. That spawn bug is why it scores lowest here, even though the engine itself is sharp.
▶ all three live — click a panel, walk (WASD), fire (space/click) · scroll on for the next build
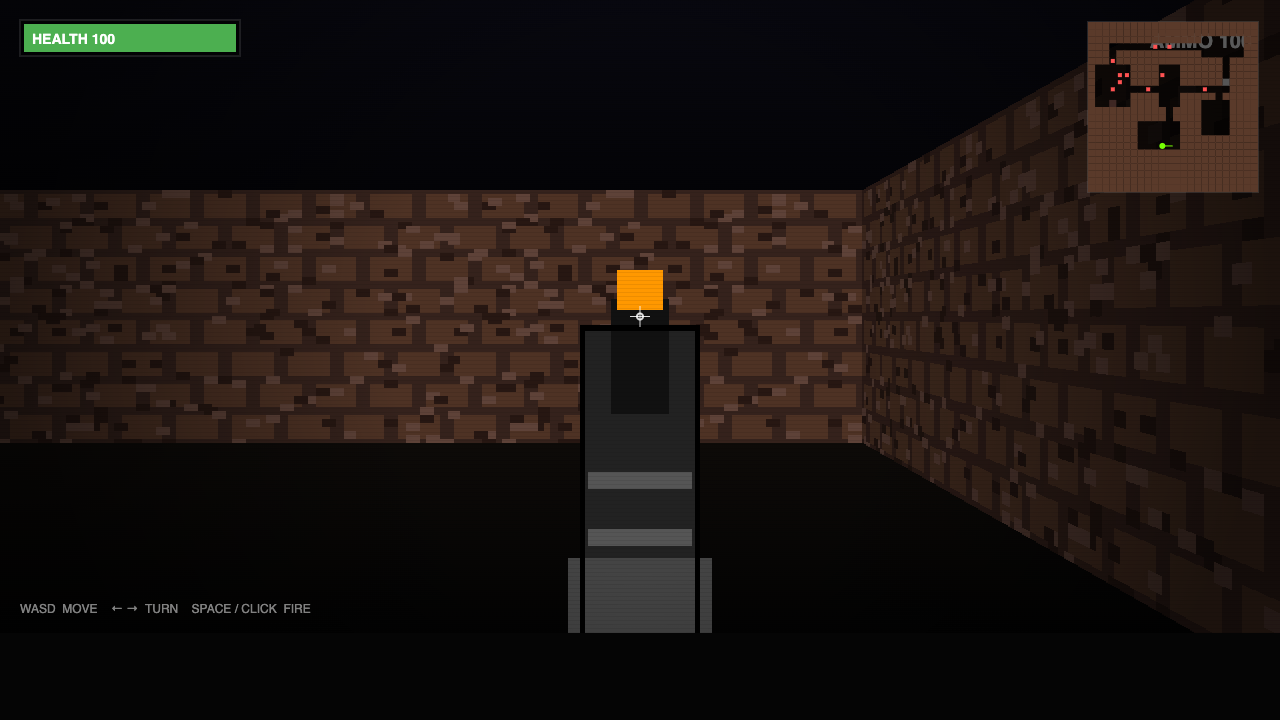
OPUS 4.8
8.5
winner · game-feel
KIMI K2.7
8.5
GLM-5.2
8
All three are real, playable shooters. Opus drops you in a corridor with an imp dead ahead — gun, crosshair and HUD framed like a screenshot. Kimi matches it: a monster down a textured hall, health, ammo, minimap. GLM ships a gorgeous "HAZARD PROTOCOL" title screen with a working game behind it, though it too spawns facing a wall. Opus by a hair on the cleanest fight.
▶ all three live — auto-flies; arrow keys nudge the steering · scroll on for the next build
GLM-5.2
9
winner · cinematic
OPUS 4.8
8.5
KIMI K2.7
7.5
GLM's is the most cinematic — neon towers, a setting sun, Japanese signage and a flight HUD, like a frame from a film. Opus's is a clean canyon of lit skyscrapers racing to a vanishing point. Kimi leaned into the synthwave sun and grid more than the city itself. GLM wins the skyline.
▶ all three live — arrows / WASD to steer + accelerate · scroll on for the next build
GLM-5.2
8.5
winner · most complete
OPUS 4.8
8.5
KIMI K2.7
8
GLM shipped the full arcade package — an "OUTRUN 2086" title, gear, RPM and velocity dials, mountains, the car cruising at 90+. Opus's road curves hard past rumble strips and palms into a scanline sun. Kimi's "NEON OUTRUN" is clean and on-brief. GLM edges it on sheer completeness.
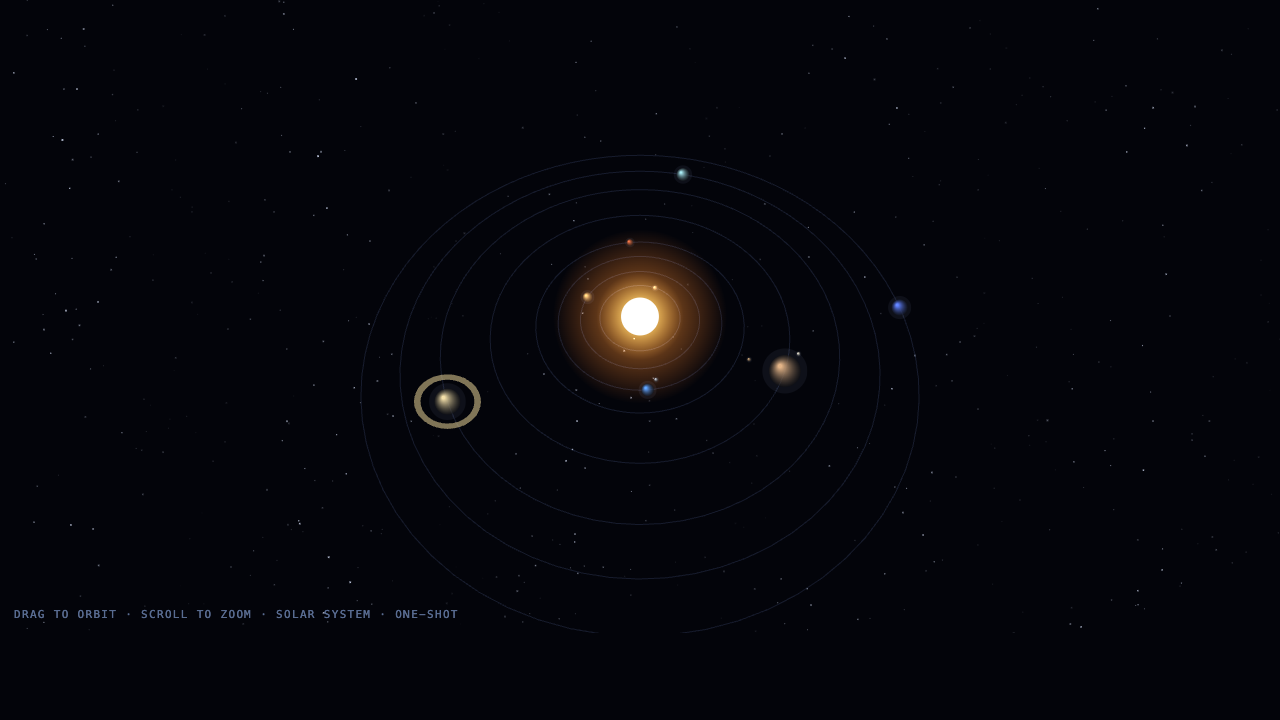
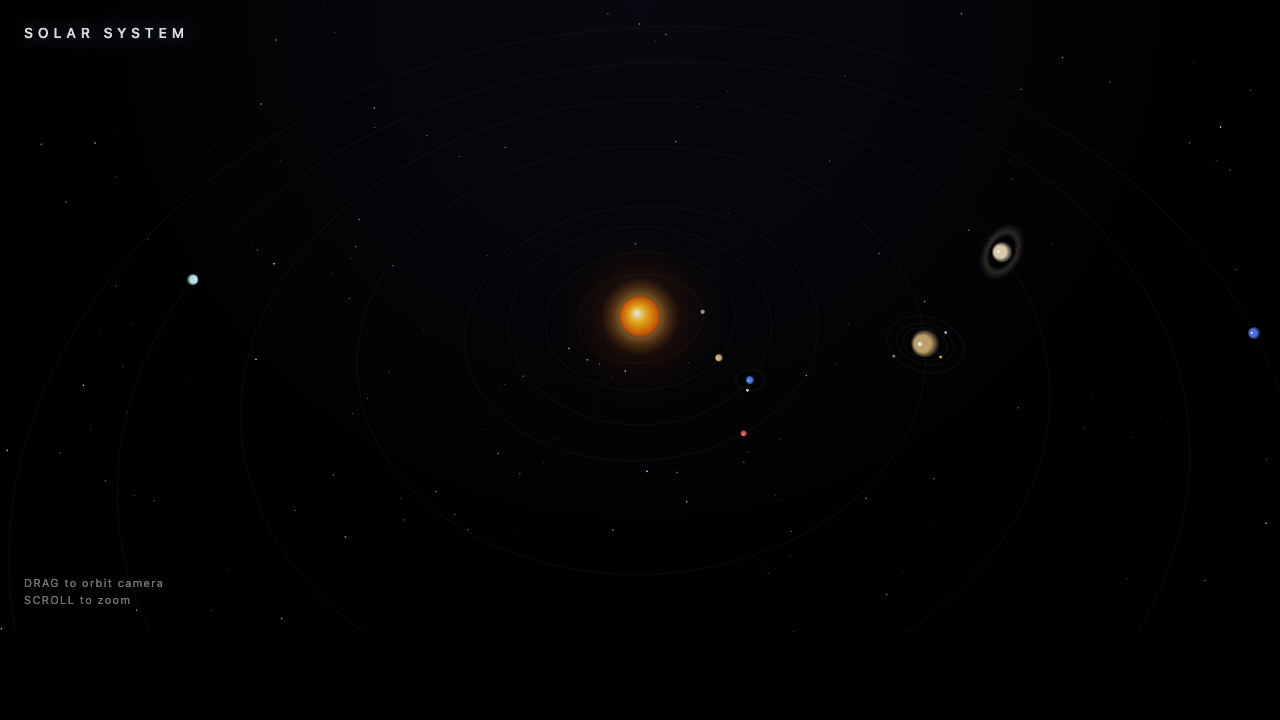
▶ all three live — drag to orbit, scroll to zoom · scroll on for the original nine
OPUS 4.8
8.5
winner · 3D depth
GLM-5.2
8.5
KIMI K2.7
8
Three genuinely good space sims. Opus tilts the orbits into real 3D with a bloom-heavy sun and Saturn's rings. GLM's is the most product-like — labelled planets, orbit and label toggles, a clean HUD. Kimi's is a tidy tilted-orbit system with rings and a deep starfield. Opus and GLM are neck-and-neck; Opus takes it on the 3D feel.
The five that started it — a voxel runner, an orbit visualiser, a fluid sim, a landing page, a neon arcade game — plus four pure-spectacle prompts: a galaxy, a black hole, a Mandelbrot zoom and a Tron terrain.
Test 1 · voxel runner
Temple-Run voxel runner (Three.js).
One shot: an endless third-person voxel runner through a procedural city — dodge blocks, grab coins, speed ramps up.
▶ all three live — click a panel and play · scroll on for the next test (off-screen builds pause to stay smooth)
GLM-5.2
9
winner · flair
OPUS 4.8
8.5
KIMI K2.7
6
GLM built the densest, most detailed city — windowed skyscrapers, a speed + coins HUD. Opus ran the furthest with the cleanest motion (Score 303). Kimi's runner plays fine but is unforgiving — it crashes within seconds.
▶ all three live — click a panel and play · scroll on for the next test (off-screen builds pause to stay smooth)
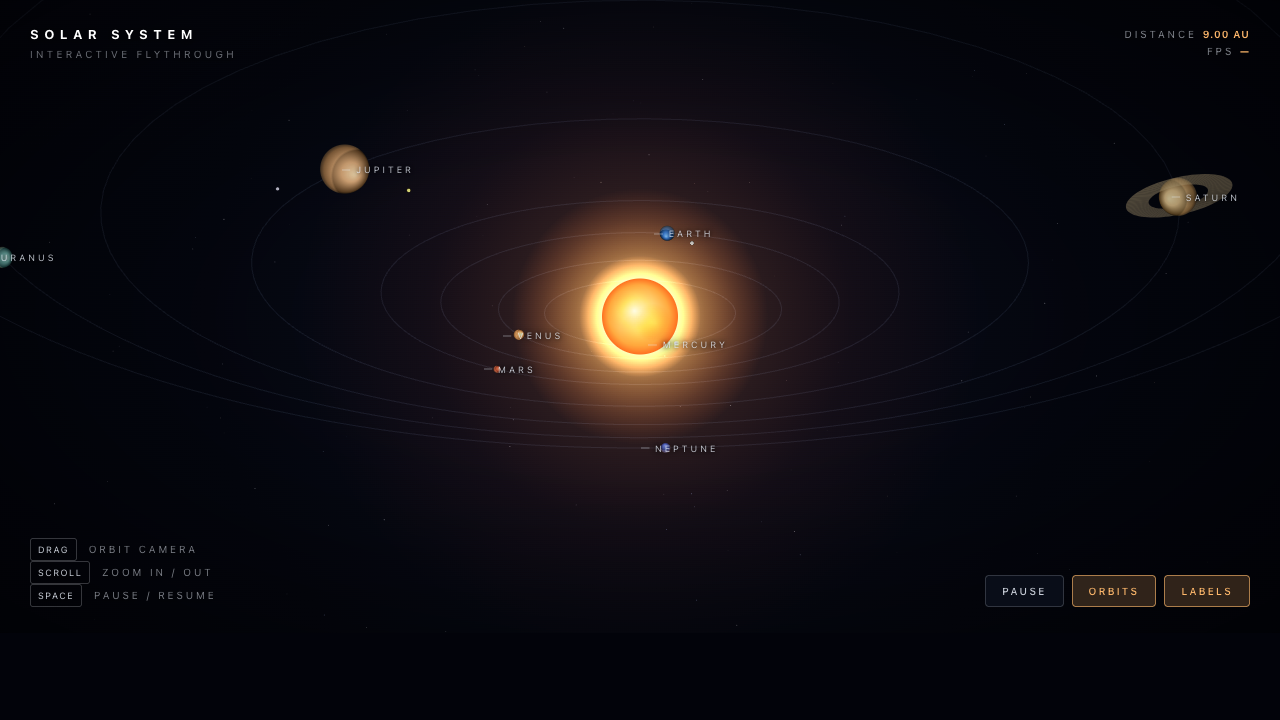
OPUS 4.8
9
winner · accuracy
GLM-5.2
7.5
KIMI K2.7
6
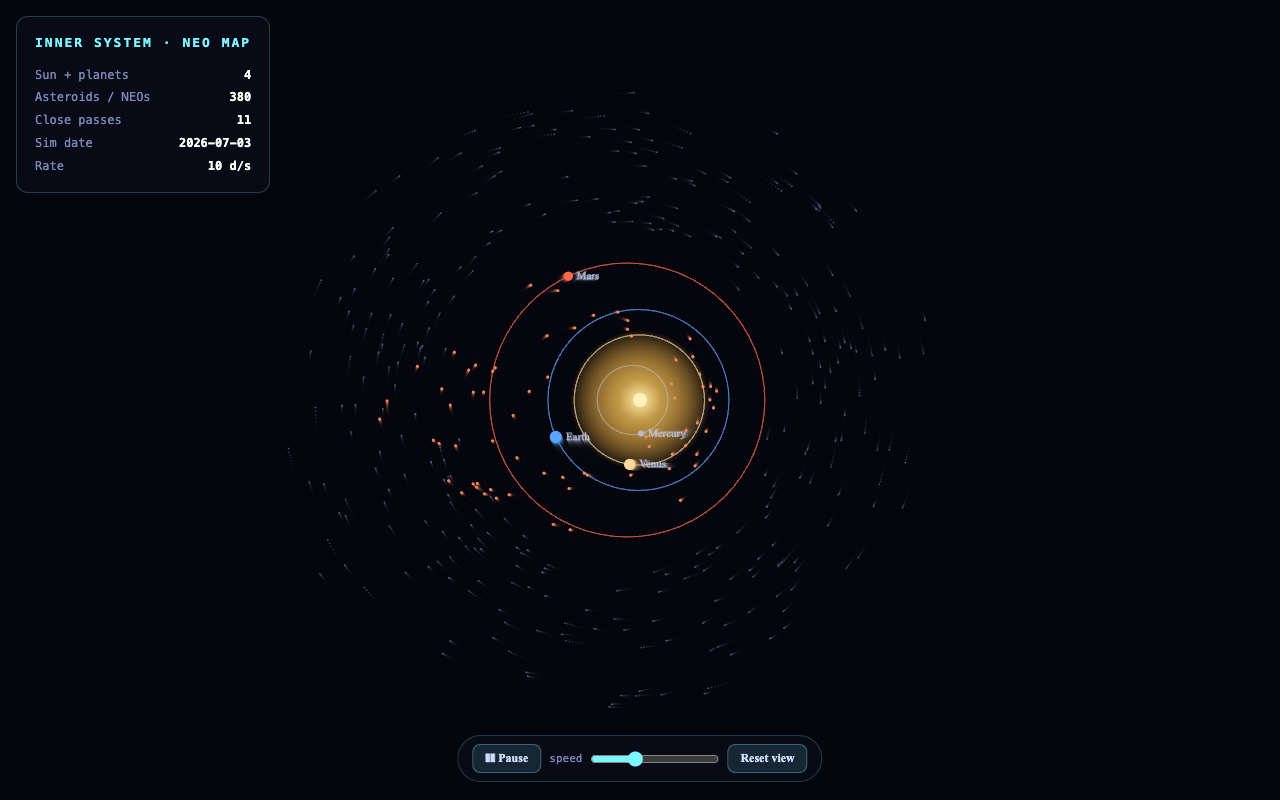
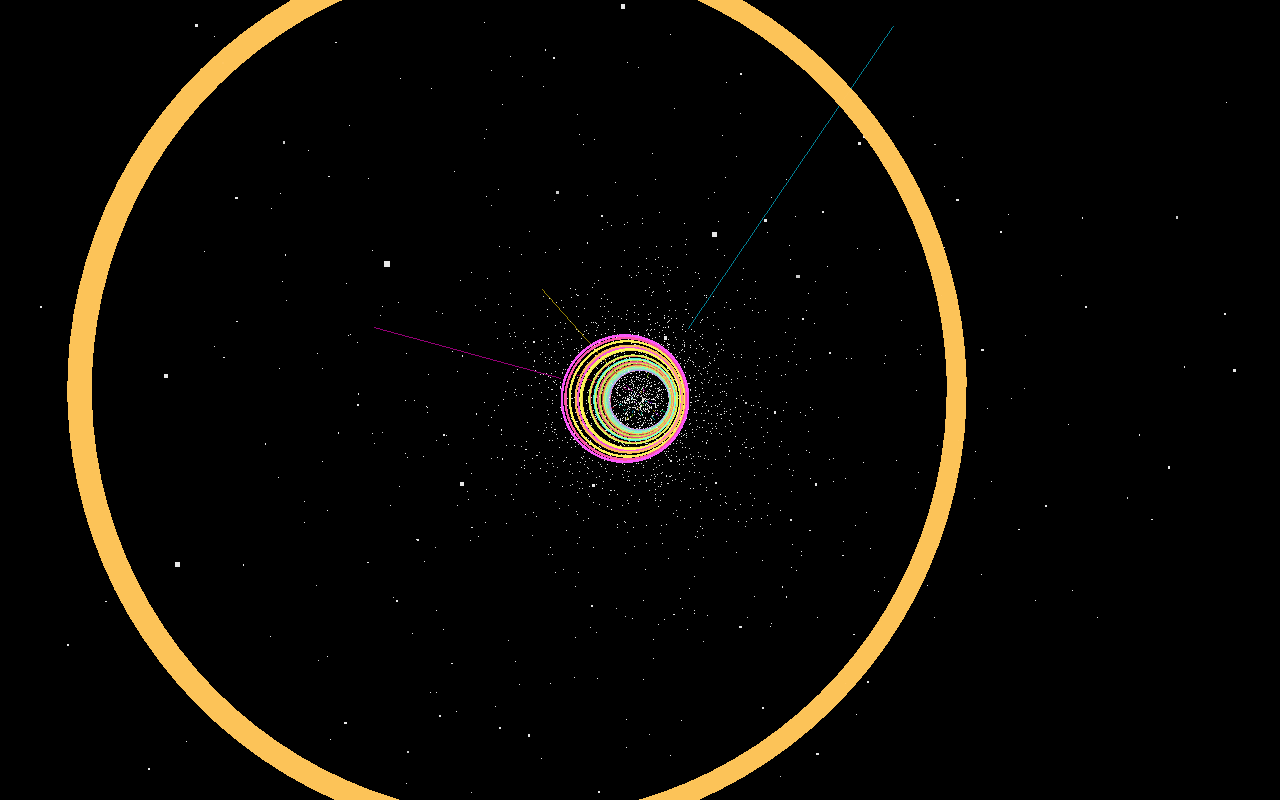
Opus nailed the brief — labelled planet orbits, a real NEO / close-pass panel, a sim clock. GLM went for drama: a glowing nebula swirl that's gorgeous but reads more galaxy than orbit map. Kimi's is accurate but dim and sparse.
▶ all three live — click a panel and play · scroll on for the next test (off-screen builds pause to stay smooth)
GLM-5.2
9
winner · best liquid
OPUS 4.8
7
KIMI K2.7
5
GLM filled the bowl with glowing liquid that actually sloshes — the most convincing "liquid in a bowl". Opus's particles glowed but clumped to the centre. Kimi's collapsed into a tiny blob.
▶ all three live — click a panel and play · scroll on for the next test (off-screen builds pause to stay smooth)
GLM-5.2
9
tie · top
OPUS 4.8
9
tie · top
KIMI K2.7
6.5
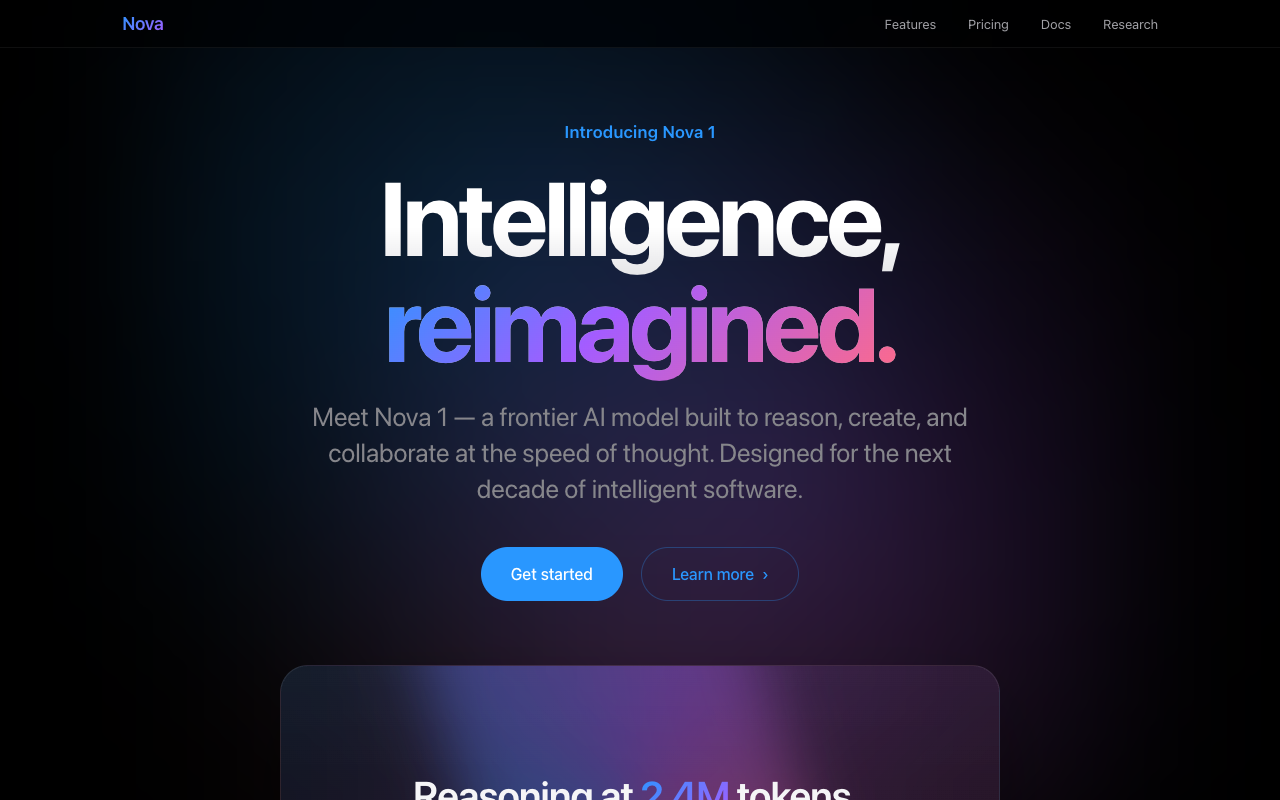
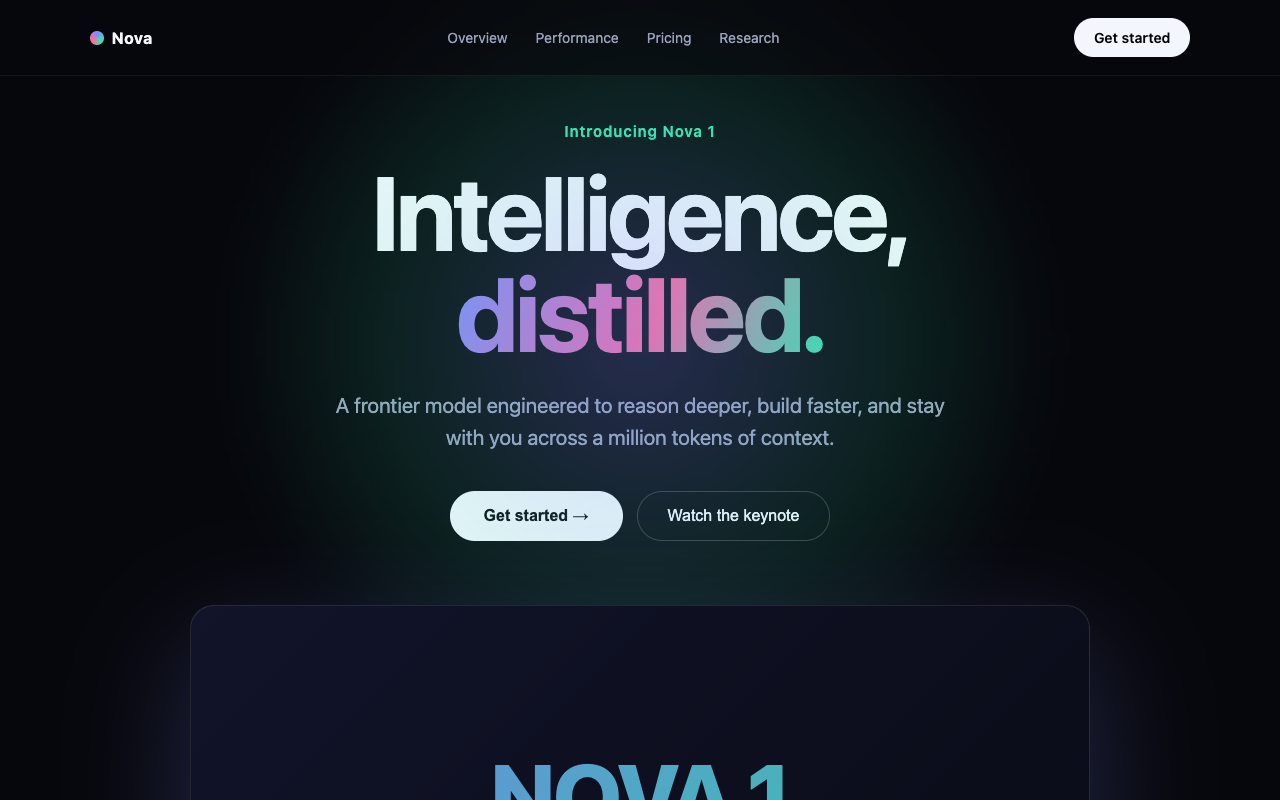
Funniest result of the lot: GLM and Opus independently produced near-identical premium "Introducing Nova 1 — Intelligence, reimagined / distilled" keynote pages — gradient hero, full nav, pricing tiers. A dead heat. Kimi's was a plainer set of feature cards.
▶ all three live — click a panel and play · scroll on for the next test (off-screen builds pause to stay smooth)
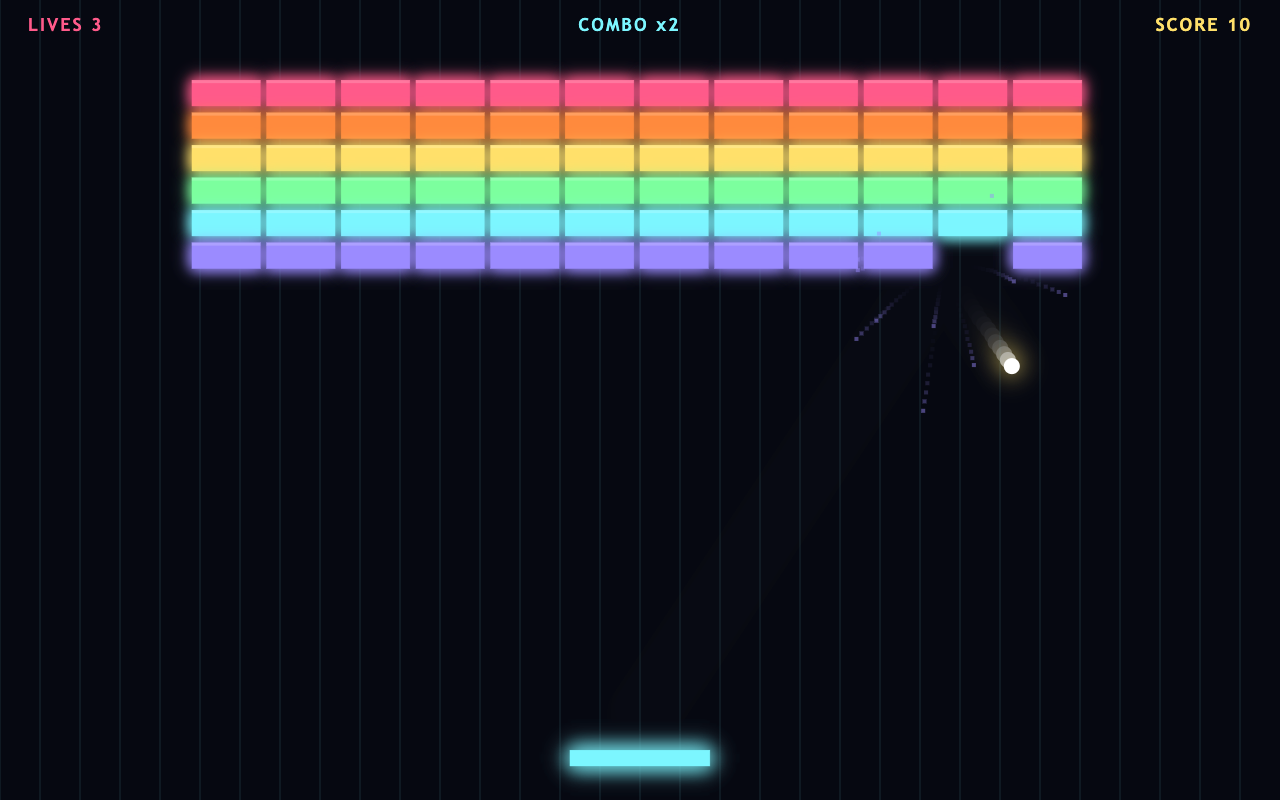
OPUS 4.8
8.5
winner · game-feel
GLM-5.2
8
KIMI K2.7
8
All three shipped a genuinely juicy game. Opus's breakout had the most game-feel — particle bursts and a live combo. Kimi's breakout was clean and solid. GLM went its own way with fullscreen neon asteroids. The closest of the practical five.
▶ all three live — click a panel and drag to orbit · scroll on for the next test (off-screen builds pause to stay smooth)
OPUS 4.8
8.5
winner · interactive 3D
KIMI K2.7
8
GLM-5.2
8
Opus built a proper interactive 3D galaxy — drag to orbit a 7,000-star cloud around a glowing core. Kimi's is the prettiest single frame: a clean tilted spiral disk with rainbow arms. GLM's runs on a canvas with a slick NGC-style HUD and zoom, just less dramatic at a glance. Three good galaxies, three different bets.
One shot: a Gargantua-style black hole — a black event horizon, a glowing accretion disk, a bright photon ring, gravitational lensing, a warped starfield.
▶ all three live — click a panel to interact · scroll on for the next test (off-screen builds pause to stay smooth)
OPUS 4.8
9
winner · hit the brief
GLM-5.2
8
KIMI K2.7
6
Opus nailed it — a pure-black event horizon, a bright photon ring, and the disk bent up and over the top exactly like the film's lensing. GLM came in strong with a clean ring and a starfield warping past the hole. Kimi's disk is fine, but the background is a soft grey blur instead of stars. This one's Opus's.
▶ all three live — click a panel to interact · scroll on for the next test (off-screen builds pause to stay smooth)
KIMI K2.7
9
winner · pure wow
OPUS 4.8
8.5
GLM-5.2
8
All three are genuinely good. Kimi's is the jaw-dropper — a deep rainbow plunge into a seahorse spiral, dense with self-similar detail. Opus zooms smoothly into the seahorse valley with a tasteful cycling palette. GLM frames the whole iconic set in a fire palette with a live coordinate HUD, then descends. Kimi takes this one on raw spectacle.
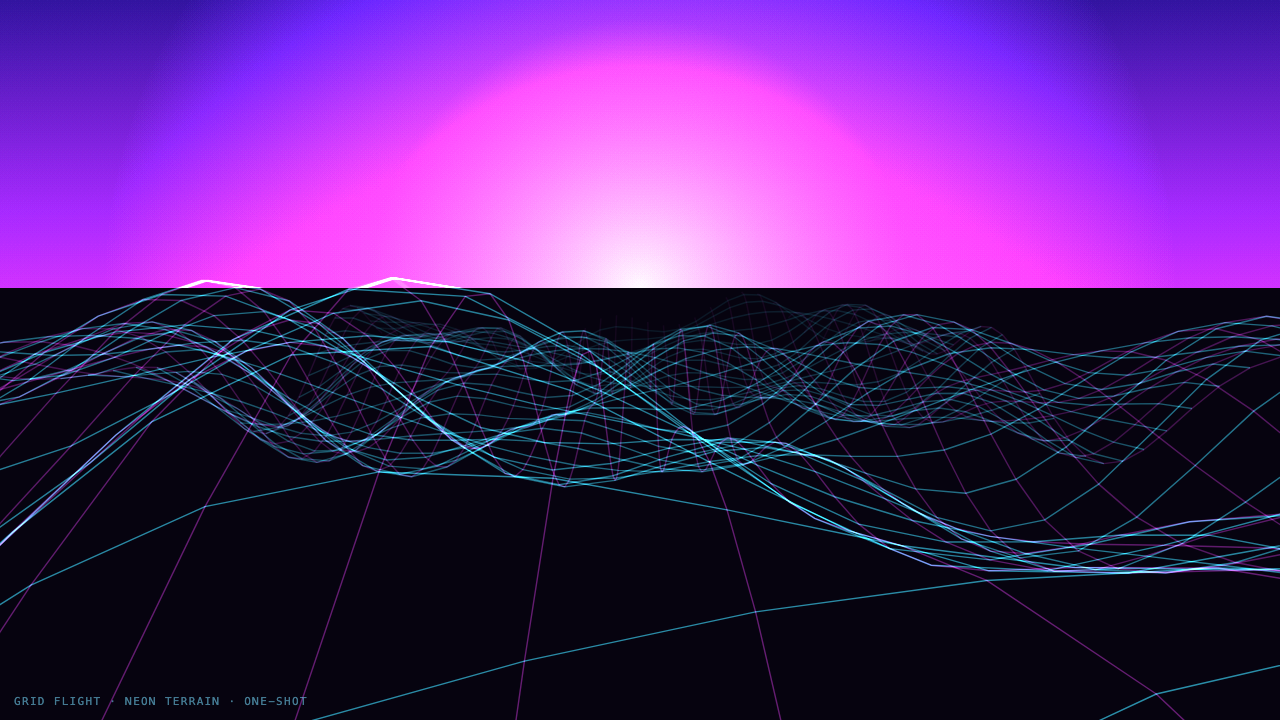
One shot: a Tron-style neon wireframe terrain flying toward the camera, a synthwave sunset on the horizon, a dark starry sky, additive glow on the grid.
▶ all three live — click a panel to interact · scroll on for the bonus round (off-screen builds pause to stay smooth)
GLM-5.2
9
winner · best frame here
OPUS 4.8
8
KIMI K2.7
6.5
This is GLM's. A cyan wireframe mountain range scrolling under a scanline synthwave sun — the single most beautiful frame in the whole shoot-out. Opus's clean Tron grid and magenta horizon is a close, cooler-toned second. Kimi got the idea but blew the exposure — the grid washes out to near-white. GLM wins this one going away.
Kimi looked plainest on the practical head-to-heads up top — so here's the same model let off the leash, full-screen and solo, on purely-visual briefs. Same model, one shot, single HTML file each. This is what Kimi K2.7 does when you ask it to show off.
▶ six solo Kimi K2.7 builds — all live, click any panel to interact
The synthwave drive and the Mandelbrot explorer are the standouts — a scanline sun over a neon grid, and a sharp colour-cycling fractal. Proof that Kimi's flat showing on the practical head-to-heads was about the briefs, not the model: give it an ambitious visual target and it delivers.
Across the practical head-to-heads up top, Kimi looked the plainest. So I gave Kimi K2.7 on its own a full set of prompts built for pure visual wow — galaxies, black holes, fractals, aurora, a Tron terrain — single HTML file, one shot, no follow-ups, straight through Agent OS. Same model that "looked plain" on a runner. Watch what happens when the whole brief is be beautiful.
▶ all twelve are live & auto-playing — drag the galaxy, scroll the fractal, fly the terrain · off-screen builds pause to stay smooth
Every panel is a single self-contained HTML file Kimi K2.7 wrote in one shot inside Agent OS — no edits, no asset packs, no second prompt. The "plain" model turns out to have serious range. You just have to ask for it.
One line each. Drop any of these into Agent OS with Kimi K2.7 selected and you get a single playable HTML file back. Tweak a noun, get a new toy.
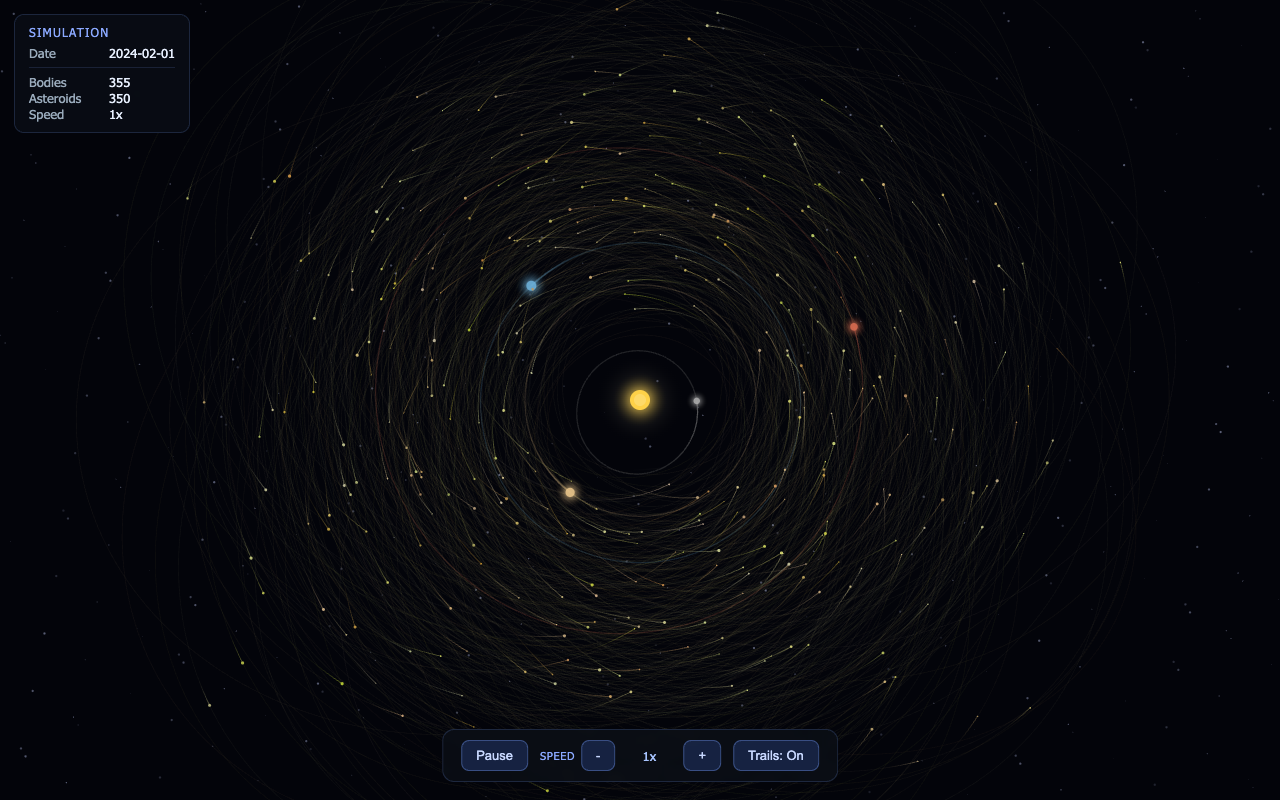
🌌 Spiral Galaxy — "A 3D spiral galaxy of 60,000 glowing particles that auto-rotates and orbits on mouse-drag, gold core to cyan arms, starfield behind."
🕳️ Black Hole — "A cinematic raymarched black hole with a glowing accretion disk and gravitational lensing of a starfield — make it look like Interstellar."
🌀 Mandelbrot Zoom — "An interactive Mandelbrot explorer in a WebGL shader: smooth colouring, psychedelic colour-cycling, slow auto-zoom on load, scroll-to-zoom + drag-to-pan."
🛣️ Synthwave Drive — "An infinite 80s synthwave drive: neon wireframe grid road scrolling to the horizon, giant gradient sun with scanlines, mountain silhouettes, looping forever."
⛰️ Tron Terrain — "An infinite flight over a procedural neon wireframe terrain under a synthwave sky with a low sun, like flying over the Tron landscape, looping forever."
🌈 Neon Wormhole — "An endless flight through a glowing neon wormhole tunnel: rings of light rushing past forever, shifting cyan-to-magenta colours, hypnotic and psychedelic."
🌠 Aurora Borealis — "Flowing ribbons of green, teal and magenta northern lights rippling over a starry sky, a dark mountain silhouette and its reflection in a still lake."
🌊 Ocean Of Light — "An undulating 3D wave field of thousands of glowing dots rippling like the ocean, colours shifting cyan to violet, slow hypnotic motion, drifting camera."
🫧 Lava Lamp — "A gooey metaball lava lamp: glowing blobs slowly rising, falling and merging in a capsule, hot-pink-through-purple-to-cyan, soft glow."
💾 Matrix Rain — "The classic Matrix digital rain: columns of glowing green katakana and digits cascading with bright leading characters and fading trails."
🎆 City Fireworks — "An automatic neon fireworks display over a dark city skyline and water reflection: rockets launch and burst into colourful sparks, repeating forever."
🐟 Flocking Swarm — "A 3D boids simulation: ~400 glowing fish swarming with separation/alignment/cohesion, one red predator they flee, motion trails, orbiting camera."
✦
The benchmark question
What about official benchmarks?
Straight answer: there aren't clean ones for these exact versions yet. z.ai shipped GLM-5.2 with no scorecard (open weights + standalone API came after), and Moonshot has only published its own proprietary benchmarks for K2.7 — it reports +21.8% on Kimi Code Bench v2, +11% on Program Bench and +31.5% on its multi-language MLS Bench Lite over K2.6, while cutting thinking tokens ~30%. Impressive gains, but they're Moonshot's own benches — no independent SWE-bench Verified for K2.7 yet. So the head-to-head above is the most honest GLM-5.2-vs-K2.7 data going.
Latest verifiable public numbers — SWE-bench Verified
Previous-generation, vendor-reported, directional only. The current 5.2 / 2.7 / 4.8 coding scores are not yet independently published.
GLM-5 (prev gen)
77.8%
Kimi K2.6 (prev gen)
80.2%
Kimi K2.7-Code — what Moonshot actually shipped
K2.7-Code launched 12 Jun 2026 with proprietary benchmarks only — every number below is a gain over K2.6, not a standard SWE-bench score.
MLS Bench Lite · multi-language — gain vs K2.6
+31.5%
Kimi Code Bench v2 — gain vs K2.6
+21.8%
Program Bench — gain vs K2.6
+11%
Plus roughly 30% fewer "thinking" tokens than K2.6, and open weights (a 1-trillion-parameter mixture-of-experts). The catch: those are all Moonshot's own benches. An independent SWE-bench Verified score for K2.7 still isn't out — K2.6 sat at 80.2%, so the bar it's chasing is high, and some practitioners have flagged that the launch numbers are hard to reproduce.
Read this before you quote any of it ↓
The 14-test scoreboard is real — my own builds, my own scoring — but it's 14 prompts and one person's eye, not a statistical benchmark.
Scores reward "ran + hit the brief + looked good" in one shot. A second prompt would change everything.
The SWE-bench bars are previous-gen (GLM-5, K2.6) and vendor-reported — there's no verified GLM-5.2 / K2.7 / Opus 4.8 coding benchmark published yet.
Different day, different prompts, you'd get a different order. This is a snapshot, not a verdict.
Run your own
Want all three coders in one place?
Every model here runs inside the Agent OS — Kimi, GLM-5.2 and Claude in one dashboard, one workspace, builds previewing live. Set it up, run your own head-to-heads, keep the winners.
The AI Profit Boardroom is where the actual Agent OS lives — the templates, the prompts, the daily rooms, the weekly walkthroughs. Same builds you read about here, taught hands-on inside.